您现在的位置是:首页 >其他 >【深入浅出Spring Security(五)】自定义过滤器进行前后端登录认证网站首页其他
【深入浅出Spring Security(五)】自定义过滤器进行前后端登录认证
一、自定义过滤器
在【深入浅出Spring Security(二)】Spring Security的实现原理 中小编阐述了默认加载的过滤器,里面有些过滤器有时并不能满足开发中的实际需求,这个时候就需要我们自定义过滤器,然后填入或者替换掉原先存在的过滤器。
首先阐述一下添加过滤器的四个方法(都是HttpSecurity中的),下面方法第一个参数都是要加入的过滤器,第二个参数是针对已存在过滤器的Class对象:
addFilterAt(filter,atFilter):这个相当于线性表的插入操作,把 filter 插入在 atFilter 的位置上。addFilterBefore(filter,atFilter):这个是在 atFilter 前插入一个 filter 过滤器;addFilterAfter(filter,atFilter):这个顾名思义是在 atFilter 后插入一个 filter 过滤器;
自定义登录认证过滤器
在 【深入浅出Spring Security(三)】默认登录认证的实现原理 中小编述说过默认的用户登录认证是走的 UsernamePasswordAuthenticationFilter,它是通过表单数据传输的方式,然后通过 request.getParameter(username/password) 的方式获取用户名密码进行认证的。但在前后端分离中,当提交登录数据给后端是 JSON 格式的话,咱就要自定义过滤器去处理这个数据获取用户名和密码进行认证了。
既然是换了一种登录认证过滤器,而且用于前后端分离,咱就可以把一些不必要的默认过滤器给pass掉。当我们调用 HttpSecurity 中的 formLogin() 方法的时候,会帮我们加载如下圈到的三个过滤器。
- UsernamePasswordAuthenticationFilter:负责表单认证的;
- DefaultLoginPageGeneratingFilter:提供登录界面的;
- DefaultLogoutPageGeneratingFilter:提供注销界面的;
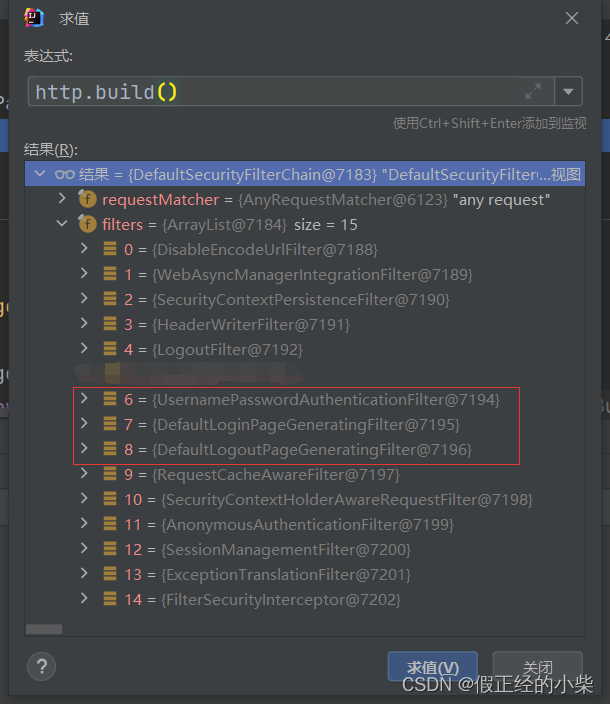
那当我们在自定义 SecurityFilterChain 的时候不去调用 formLogin 方法的话,那这三个过滤器就相当于被我们 pass 掉了。
自定义 LoginFilter
既然咱要去实现一个 JSON 数据格式的认证,首先得先对请求进行一些判断:
- 请求方式应该是 POST 方式;
- 请求发来的数据应该是 JSON 格式的。
不满足这些的话,应该去采取默认配置的登录认证。
实现方式很简单:
咱去继承 UsernamePasswordAuthenticationFilter 重写 attemptAuthentication 方法,实现自己的认证方式即可。
代码如下:
public class LoginFilter extends UsernamePasswordAuthenticationFilter {
public LoginFilter() {
}
public LoginFilter(AuthenticationManager authenticationManager) {
super(authenticationManager);
}
@Override
public Authentication attemptAuthentication(HttpServletRequest request, HttpServletResponse response)
throws AuthenticationException {
// 判断请求方式是否是 POST 方式
if (!request.getMethod().equals("POST")) {
throw new AuthenticationServiceException("Authentication method not supported: " + request.getMethod());
}
// 然后判断是否是 JSON 格式的数据
if(request.getContentType().equalsIgnoreCase(MediaType.APPLICATION_JSON_VALUE)) {
// 如果是的话就从 JSON 中取出用户信息进行认证
try {
Map<String,String> userInfo = JSONObject.parseObject(request.getInputStream(), Map.class);
String username = userInfo.get(getUsernameParameter());
String password = userInfo.get(getPasswordParameter());
// 封装成Authentication
UsernamePasswordAuthenticationToken authRequest = UsernamePasswordAuthenticationToken.unauthenticated(username,
password);
// 仿造父类去调用AuthenticationManager.authenticate认证就可以了
setDetails(request,authRequest);
return getAuthenticationManager().authenticate(authRequest);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 否则用父类的方式去认证
return super.attemptAuthentication(request, response);
}
}
配置 LoginFilter
这里使用的新版本的注入方式,而不是使用继承 WebSecurityConfigurerAdapter 的方式,因为 WebSecurityConfigurerAdapter 已经被弃用了,咱还是与时俱进吧。
@EnableWebSecurity
public class SecurityConfig {
/**
* 构造基于内存的数据源管理
* @return InMemoryUserDetailsManager
*/
@Bean
public InMemoryUserDetailsManager inMemoryUserDetailsManager(){
return new InMemoryUserDetailsManager(User
.withUsername("admin")
.password("{noop}123")
.authorities("admin")
.build()
);
}
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
return http.authorizeRequests()
.anyRequest()
.authenticated()
.and()
.logout()
.logoutSuccessHandler(this::onAuthenticationSuccess)
.logoutUrl("/api/auth/logout")
.and()
.addFilterAt(loginFilter(http), UsernamePasswordAuthenticationFilter.class) // 注意配置 filter 哦
.csrf()
.disable()
.build();
}
/**
* 自定义 AuthenticationManager
* @param http
* @return AuthenticationManager
* @throws Exception
*/
@Bean
public AuthenticationManager authenticationManager(HttpSecurity http) throws Exception {
return http.
getSharedObject(AuthenticationManagerBuilder.class)
.userDetailsService(inMemoryUserDetailsManager())
.and()
.build();
}
@Bean
public LoginFilter loginFilter(HttpSecurity http) throws Exception {
LoginFilter loginFilter = new LoginFilter(authenticationManager(http));
// 自定义 JSON 的 key
loginFilter.setUsernameParameter("username");
loginFilter.setPasswordParameter("password");
// 自定义接收的url,默认是login
// 此过滤器的doFilter是在AbstractAuthenticationProcessingFilter,在那里进行的url是否符合的判定
loginFilter.setFilterProcessesUrl("/api/auth/login");
// 设置login成功返回的JSON数据
loginFilter.setAuthenticationSuccessHandler(this::onAuthenticationSuccess);
// 设置login失败返回的JSON数据
loginFilter.setAuthenticationFailureHandler(this::onAuthenticationFailure);
return loginFilter;
}
@Resource
private ObjectMapper objectMapper;
public void onAuthenticationSuccess(HttpServletRequest request, HttpServletResponse response,
Authentication authentication) throws IOException, ServletException{
response.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
if(request.getRequestURI().endsWith("/login"))
out.write(objectMapper.writeValueAsString(JsonData.success("登录成功")));
else if(request.getRequestURI().endsWith("/logout"))
out.write(objectMapper.writeValueAsString(JsonData.success("注销成功")));
out.close();
}
public void onAuthenticationFailure(HttpServletRequest request, HttpServletResponse response,
AuthenticationException exception) throws IOException, ServletException{
response.setContentType("text/html;charset=utf-8");
PrintWriter out = response.getWriter();
out.write(objectMapper.writeValueAsString(JsonData.failure(401,exception.getMessage())));
out.close();
}
}
测试
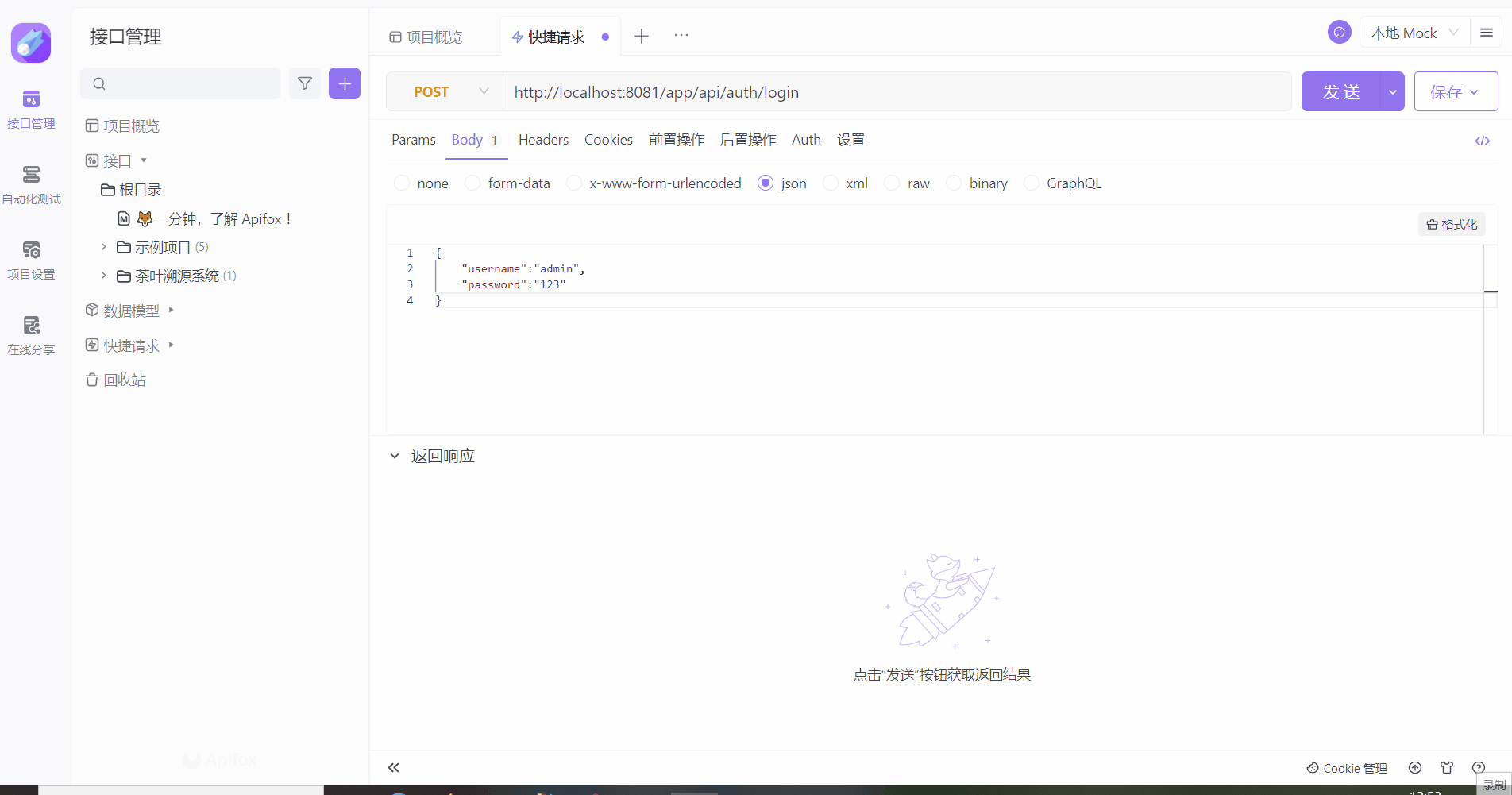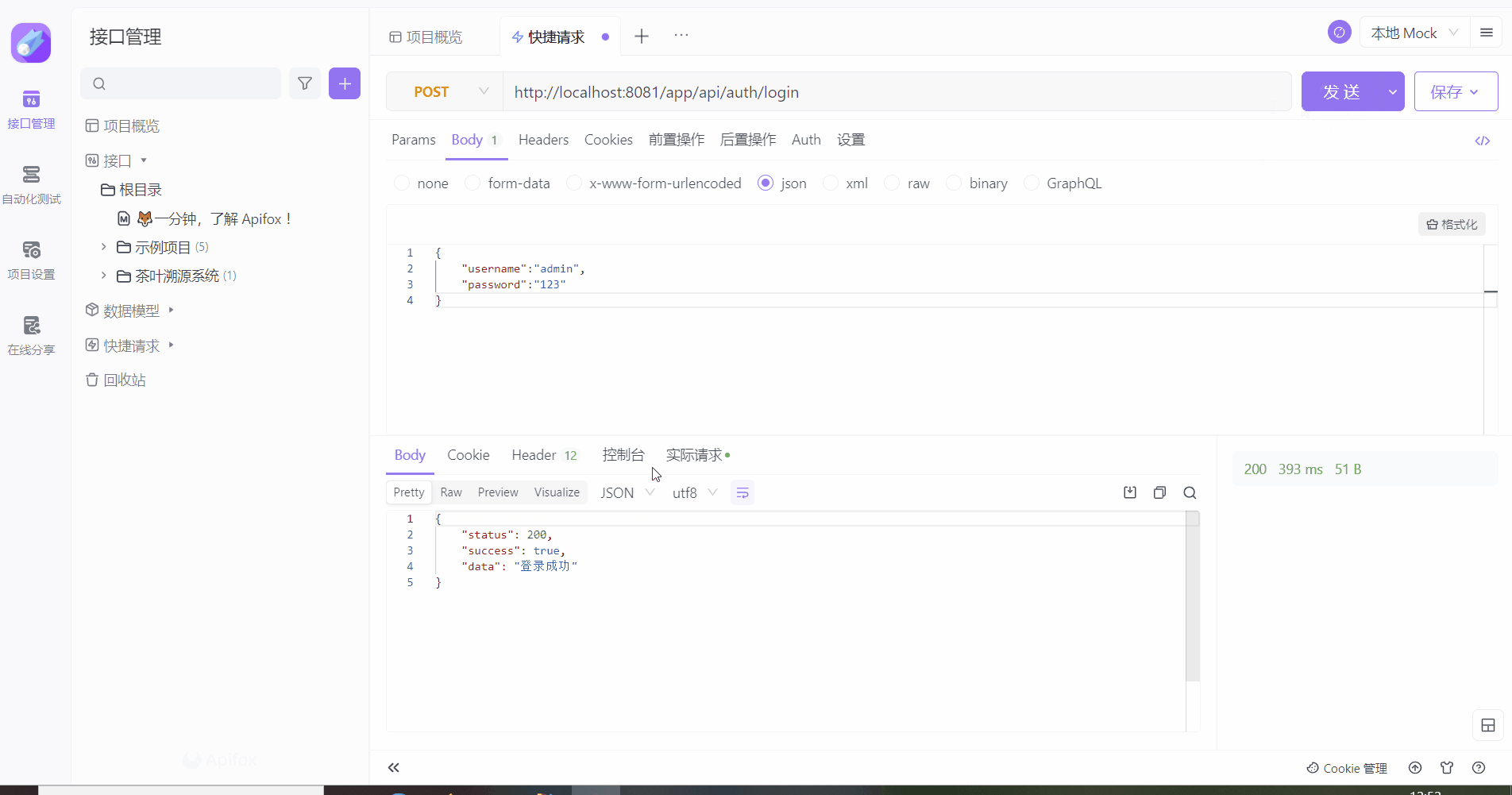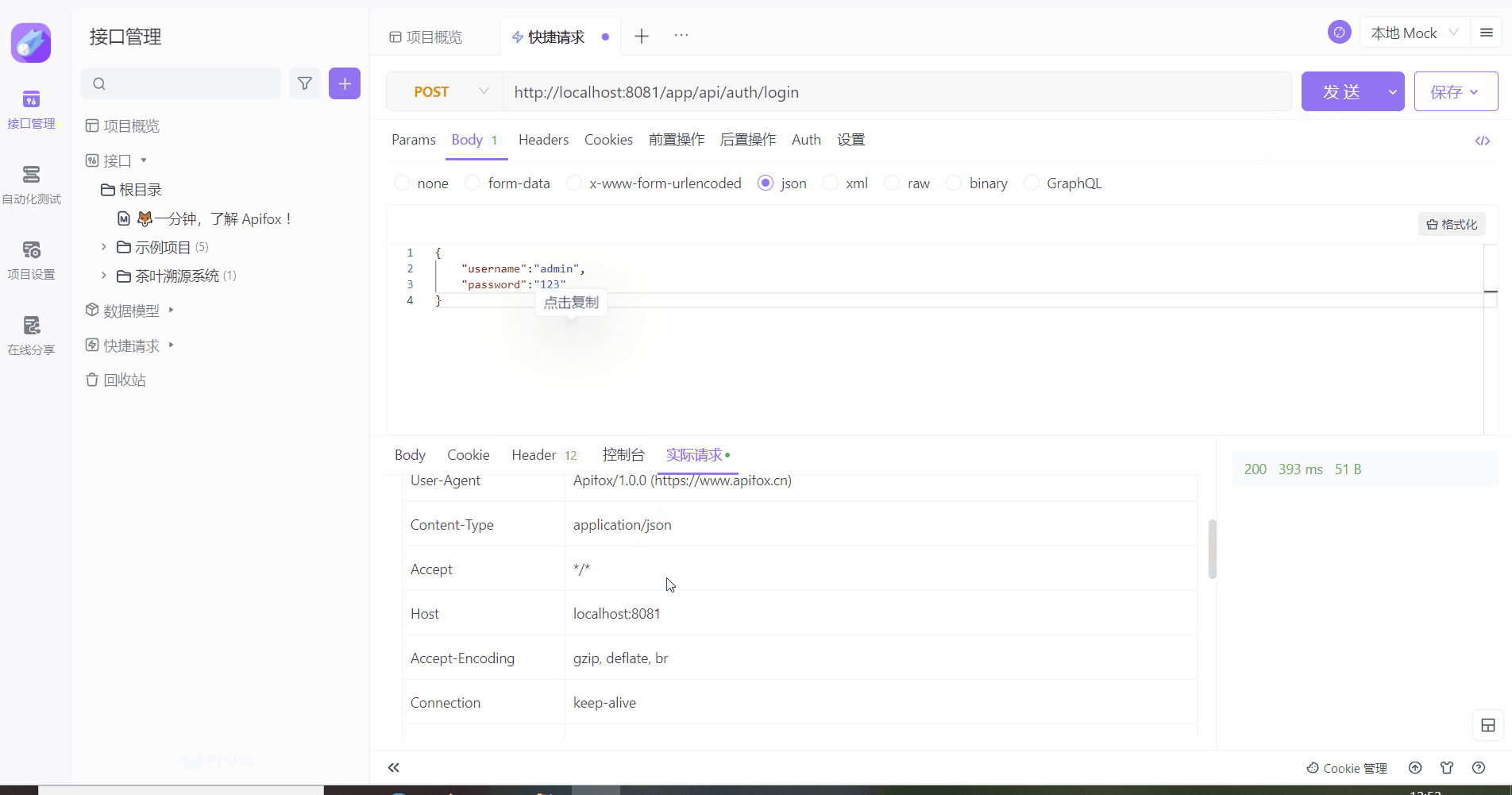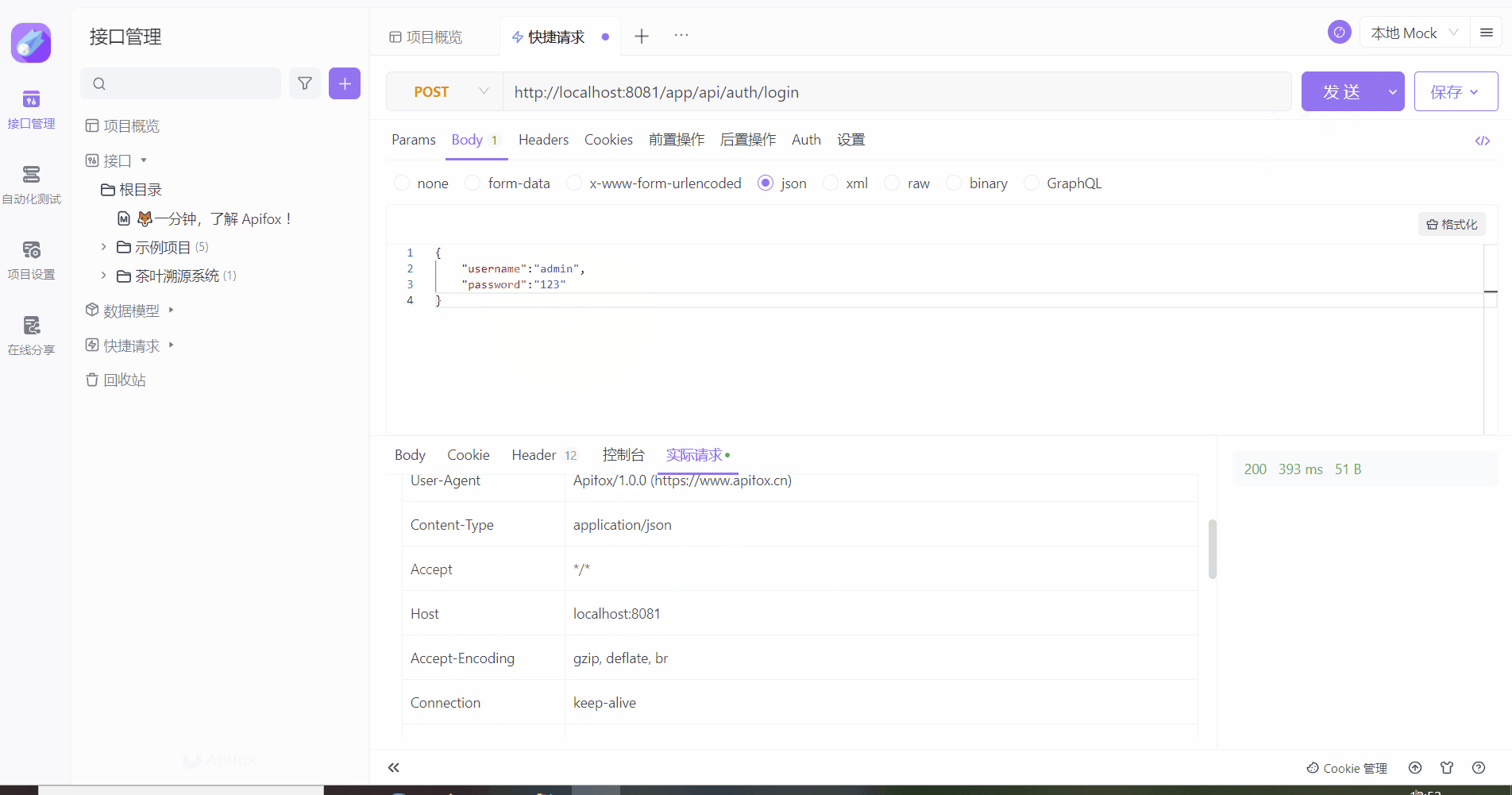
二、总结
- HttpSecurity 中可以用来添加过滤器的三个方法:
addFilterAt(filter,atFilter):这个相当于线性表的插入操作,把 filter 插入在 atFilter 的位置上。addFilterBefore(filter,atFilter):这个是在 atFilter 前插入一个 filter 过滤器;addFilterAfter(filter,atFilter):这个顾名思义是在 atFilter 后插入一个 filter 过滤器;
- 自定义登录认证可以去继承 UsernamePasswordAuthenticationFilter 过滤器重写 attemptAuthentication 方法进行自定义,然后再在自定义的 SecurityConfig 配置类里面去将它配置到 Spring 容器中,注意实例化它后一定要给它内部属性 AuthenticationManager 进行初始化赋值,不然交给Spring容器管理的时候会报错;最后添加到过滤器链中。
- 不去调用 formLogin 方法,那下面三个过滤器在过滤器链 SecurityFilterChain 中。
UsernamePasswordAuthenticationFilter:负责表单认证的;
DefaultLoginPageGeneratingFilter:提供登录界面的;
DefaultLogoutPageGeneratingFilter:提供注销界面的;






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结