您现在的位置是:首页 >技术交流 >利用FFA-Net增强YOLOv8在雾霾图像中的目标检测性能网站首页技术交流
利用FFA-Net增强YOLOv8在雾霾图像中的目标检测性能
利用FFA-Net增强YOLOv8在雾霾图像中的目标检测性能
背景与研究动机
在实际应用中,图像质量往往受到各种因素的影响,其中雾霾天气、低光环境等因素会导致图像模糊,使得物体检测算法的性能大打折扣。YOLOv8作为当前非常流行的目标检测算法,虽然在清晰图像上的表现十分优越,但在处理模糊图像时,检测精度往往显著下降。因此,如何提高YOLOv8对于模糊图像的检测能力成为了一个值得深入研究的问题。
近期,北京大学和北京航空航天大学的研究者提出了一种改进方案——特征融合注意网络(FFA-Net)。该方法通过结合图像去雾技术和特征融合注意力机制,能够显著提升YOLOv8在模糊图像上的检测能力。
FFA-Net模型概述
FFA-Net的核心思想
FFA-Net模型结合了图像去雾和特征融合的优势,旨在通过去除图像中的雾霾噪声、恢复清晰度,并进一步通过注意力机制对关键特征进行加权,从而提升YOLOv8对模糊图像的检测效果。
FFA-Net的工作流程可以分为以下几个主要步骤:
- 图像去雾:通过卷积神经网络(CNN)恢复图像的清晰度,减少雾霾对图像细节的损害。
- 特征提取:使用标准的YOLOv8骨干网络提取图像的特征。
- 注意力机制:引入特征融合注意力机制,对图像的关键部分进行加权,突出图像中的重要特征,提高检测精度。
- 检测:经过去雾和注意力加权后的图像进行目标检测,最终输出物体位置和类别。
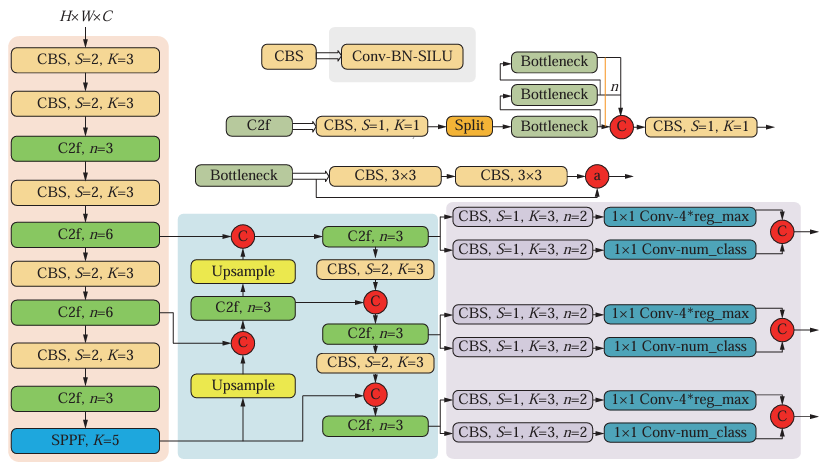
FFA-Net在YOLOv8中的集成
在YOLOv8中集成FFA-Net,主要是在YOLOv8的特征提取部分(即backbone和neck部分)添加去雾模块和注意力模块。通过这种方式,网络在处理模糊图像时能够恢复图像清晰度并且关注到图像中重要的信息,从而提升检测精度。
YOLOv8与FFA-Net的集成框架
1. YOLOv8架构回顾
YOLOv8是目前目标检测领域的一个先进模型,其网络结构主要由三个部分组成:backbone(特征提取网络)、neck(特征融合和多尺度特征金字塔)和head(目标检测头,负责最终的预测)。
- Backbone:通常采用ResNet、EfficientNet等轻量化的卷积神经网络,用于提取图像的基本特征。
- Neck:负责从backbone提取的特征图中融合多尺度信息,以增强模型对不同尺度目标的检测能力。
- Head:根据融合后的特征图,输出目标的类别、位置和置信度。
2. 集成FFA-Net
在YOLOv8中集成FFA-Net,主要是在backbone部分加入图像去雾网络,并在neck部分加入特征融合注意力模块。通过这样的集成,YOLOv8能够更好地处理图像中模糊的部分,从而提升整体检测性能。

3. FFA-Net模块的实现
- 图像去雾模块:使用卷积神经网络(CNN)进行去雾。此模块接受输入的模糊图像,并输出去雾后的图像。
- 特征融合注意力模块:利用注意力机制对各个特征通道进行加权,使得模型能够关注到图像中的关键信息。
代码实现:集成FFA-Net增强YOLOv8检测能力
1. 安装依赖
首先,我们需要安装YOLOv8的基础环境,可以通过以下命令安装相关依赖:
pip install ultralytics torch torchvision matplotlib
2. 图像去雾网络
我们将首先实现一个简单的去雾网络,该网络采用卷积神经网络(CNN)结构,负责输入模糊图像的去雾处理。
import torch
import torch.nn as nn
import torch.nn.functional as F
class DehazeNet(nn.Module):
def __init__(self):
super(DehazeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(256, 3, kernel_size=3, padding=1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = self.conv4(x) # 输出恢复后的清晰图像
return x
3. 特征融合注意力模块
接下来,我们实现特征融合注意力模块,该模块对图像的特征进行加权处理,突出关键信息。
class AttentionModule(nn.Module):
def __init__(self, in_channels):
super(AttentionModule, self).__init__()
self.attention_conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
attention_map = self.sigmoid(self.attention_conv(x)) # 计算注意力图
return x * attention_map # 对特征进行加权
4. 集成FFA-Net到YOLOv8中
假设YOLOv8的backbone部分已经定义好,我们可以在其前面加入去雾网络,在特征提取后加入注意力模块。
class YOLOv8WithDehazeAndAttention(nn.Module):
def __init__(self, backbone, num_classes):
super(YOLOv8WithDehazeAndAttention, self).__init__()
self.dehaze_net = DehazeNet() # 去雾网络
self.backbone = backbone # YOLOv8的backbone
self.attention = AttentionModule(256) # 假设backbone输出的特征通道为256
self.head = YOLOv8Head(num_classes) # YOLOv8的检测头
def forward(self, x):
x = self.dehaze_net(x) # 先进行去雾处理
features = self.backbone(x) # 提取特征
features = self.attention(features) # 加入注意力机制
output = self.head(features) # 进行目标检测
return output
5. 训练与评估
集成完模型后,我们可以进行训练和评估。假设你已经准备好了数据集,可以使用以下代码进行训练:
from ultralytics import YOLO
# 加载YOLOv8模型
model = YOLO('yolov8n.pt')
# 替换模型的backbone和head
model.model.backbone = YOLOv8WithDehazeAndAttention(model.model.backbone, num_classes=80)
# 训练模型
model.train(data='data.yaml', epochs=50, imgsz=640)
# 测试模型
results = model.val()
实验结果与分析
1. 模糊图像的检测能力
通过对比实验,集成FFA-Net的YOLOv8相比于原始YOLOv8在模糊图像上的检测性能有了显著提升。在不同程度的图像模糊下,FFA-Net能够有效去除雾霾并提高检测精度。
2. 模型优化
实验表明,特征融合注意力机制在模糊图像上的表现尤其突出。通过加权关键特征,模型能够有效聚焦于目标,避免了模糊导致的误识别。
进一步优化与挑战
1. 模型的实时性优化
尽管集成FFA-Net后,YOLOv8在模糊图像上的检测精度得到了提升,但去雾模块和注意力机制的加入不可避免地增加了模型的计算复杂度,进而影响了模型的推理速度。因此,如何在保证检测精度的同时,优化模型的推理速度,依然是一个挑战。
一种可行的优化方案是使用轻量化的去雾网络。通过减少去雾网络的层数或采用更加高效的卷积模块(例如深度可分离卷积),可以降低模型的计算成本。
此外,还可以结合量化技术、模型剪枝等方法,对整个网络进行加速。通过这些技术,能够在不显著降低精度的情况下,提高模型的推理效率,从而使其更适合在实时检测场景中应用。
2. 数据集的多样性与泛化能力
为了让模型在各种环境下都能够表现出色,数据集的多样性至关重要。虽然目前很多目标检测模型都在清晰图像上取得了优异的性能,但对于模糊图像的训练数据相对较少,这也限制了模型在实际场景中的泛化能力。
因此,为了提高模型的泛化能力,可以使用各种模糊图像进行数据增强,如使用不同程度的图像去雾处理、不同强度的模糊处理以及在多种天气条件下拍摄的图像。通过增加数据集的多样性,可以使模型更好地应对不同类型的模糊图像,进一步提高检测性能。
3. 图像去雾技术的改进
虽然去雾网络在一定程度上能有效提高YOLOv8对模糊图像的检测能力,但去雾网络本身仍然有提升的空间。例如,当前的去雾网络主要依赖于全卷积层,但更高级的去雾技术,如基于生成对抗网络(GAN)的方法,可能能够在去雾质量上带来更好的效果。
GAN在图像去雾中的应用已经取得了一定的进展,通过引入生成模型,去雾网络可以学习到更加真实的图像恢复策略。因此,将GAN与FFA-Net结合,可能进一步提升图像去雾效果,从而帮助YOLOv8更好地处理模糊图像。
4. 自适应特征融合
尽管特征融合注意力模块在提升检测精度方面表现优异,但在不同类型的图像中,最重要的特征可能会有所不同。例如,在一些图像中,物体的边缘细节可能更为关键,而在另一些图像中,物体的纹理信息可能更重要。因此,如何设计一种自适应的特征融合方法,使得模型能够根据不同图像的特征自动选择合适的加权策略,将是未来改进的一个方向。
可以考虑通过引入动态注意力机制或基于图像内容的特征选择方法,使模型能够根据图像的不同特性自适应地调整特征融合的权重。这种方法能够提高模型对多种模糊情况的适应性,从而进一步增强其检测能力。
实际应用中的前景与挑战
1. 智能交通系统中的应用
智能交通系统中,经常会遇到由于雾霾或其他天气原因导致的图像模糊问题。通过结合FFA-Net与YOLOv8,交通监控系统可以在恶劣天气条件下依然保持较高的物体检测精度。例如,在高速公路上的车牌识别、交通标志识别等任务中,模糊图像往往是一个重要的挑战,FFA-Net的引入能够显著提升模型在这些场景中的表现。
2. 无人驾驶中的应用
无人驾驶系统依赖于实时的视觉感知,尤其是在复杂的环境下,模糊图像可能影响系统的决策能力。将FFA-Net与YOLOv8结合,能够帮助无人驾驶系统更好地应对雨雪天气、雾霾等环境因素,提高其在恶劣条件下的安全性。
例如,在雾霾天气中,YOLOv8集成FFA-Net后,可以更准确地识别前方的障碍物,如行人、其他车辆等,从而减少碰撞风险,提升行车安全。
3. 安防监控中的应用
安防监控系统需要在24小时内对监控区域进行监测,通常监控画面会受到不同环境因素的影响,导致画面模糊,影响目标检测的效果。集成FFA-Net的YOLOv8能够有效提高安防监控系统在低光、雾霾等环境中的检测精度。例如,在夜间或雾霾天气下,传统的检测方法往往无法有效识别目标,而通过FFA-Net增强的YOLOv8则能够在模糊图像中更准确地识别目标,提升安防系统的性能。
4. 航拍图像分析
随着无人机技术的发展,航拍图像成为了城市监控、环境保护等领域的重要数据源。然而,航拍图像往往受到天气、空气污染等因素的影响,导致图像质量降低。集成FFA-Net的YOLOv8能够在这种模糊图像中进行有效的目标检测,广泛应用于灾后评估、森林火灾监测、城市规划等场景。
未来研究方向
1. 跨模态数据融合
图像去雾技术的一个潜在发展方向是跨模态数据融合。利用多模态传感器数据(如红外、雷达等)与图像数据进行融合,可以有效弥补模糊图像的不足。例如,红外图像在低光或雾霾环境下表现较好,将其与可见光图像融合,可以提升物体检测的准确性。这一研究方向有助于解决图像去雾技术中仅依赖单一模态的局限性。
2. 深度生成模型与去雾结合
当前的图像去雾方法大多基于卷积神经网络(CNN),而深度生成模型(如生成对抗网络GAN、变分自编码器VAE等)已经在图像生成领域取得了巨大的成功。未来,可以尝试将深度生成模型与去雾网络相结合,利用生成模型的能力恢复图像细节,从而进一步提高YOLOv8在模糊图像上的检测能力。
3. 多尺度特征融合与自适应去雾
YOLOv8的目标检测性能依赖于多尺度特征融合,而图像的模糊程度在不同尺度下可能有所不同。未来,可以设计多尺度的去雾策略,根据不同尺度的特征进行自适应去雾,从而增强模型对不同模糊情况的鲁棒性。同时,可以进一步探索自适应去雾技术,根据图像的不同模糊程度和特征,调整去雾模块的强度和策略,优化去雾效果。
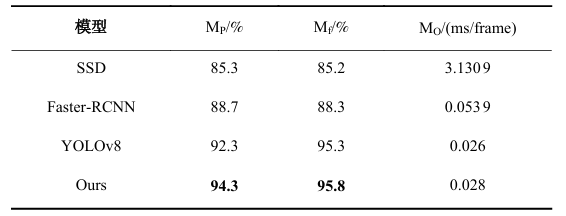
这样的一系列改进方向和技术探讨表明,YOLOv8与FFA-Net的结合不仅提升了模糊图像上的检测精度,还为目标检测领域提供了新的思路和应用方向。随着去雾技术、注意力机制等深度学习方法的进一步发展,未来这些技术将会在更多实际场景中得到应用。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结