您现在的位置是:首页 >技术教程 >Python爬虫实战:获取中药网站药物编号对应表网站首页技术教程
Python爬虫实战:获取中药网站药物编号对应表
引言
最近在做与中药材有关的项目,有获取中药实时价格的需要,因此就需要通过程序从网络上获取到中药的价格。
分析
在网上随便搜了搜,发现这个网站的药材种类要多一点,可能会符合采集需求,因此来到这个网站进行分析。
我们随便使用一下这个网站的各功能,观察网页页面的变化。
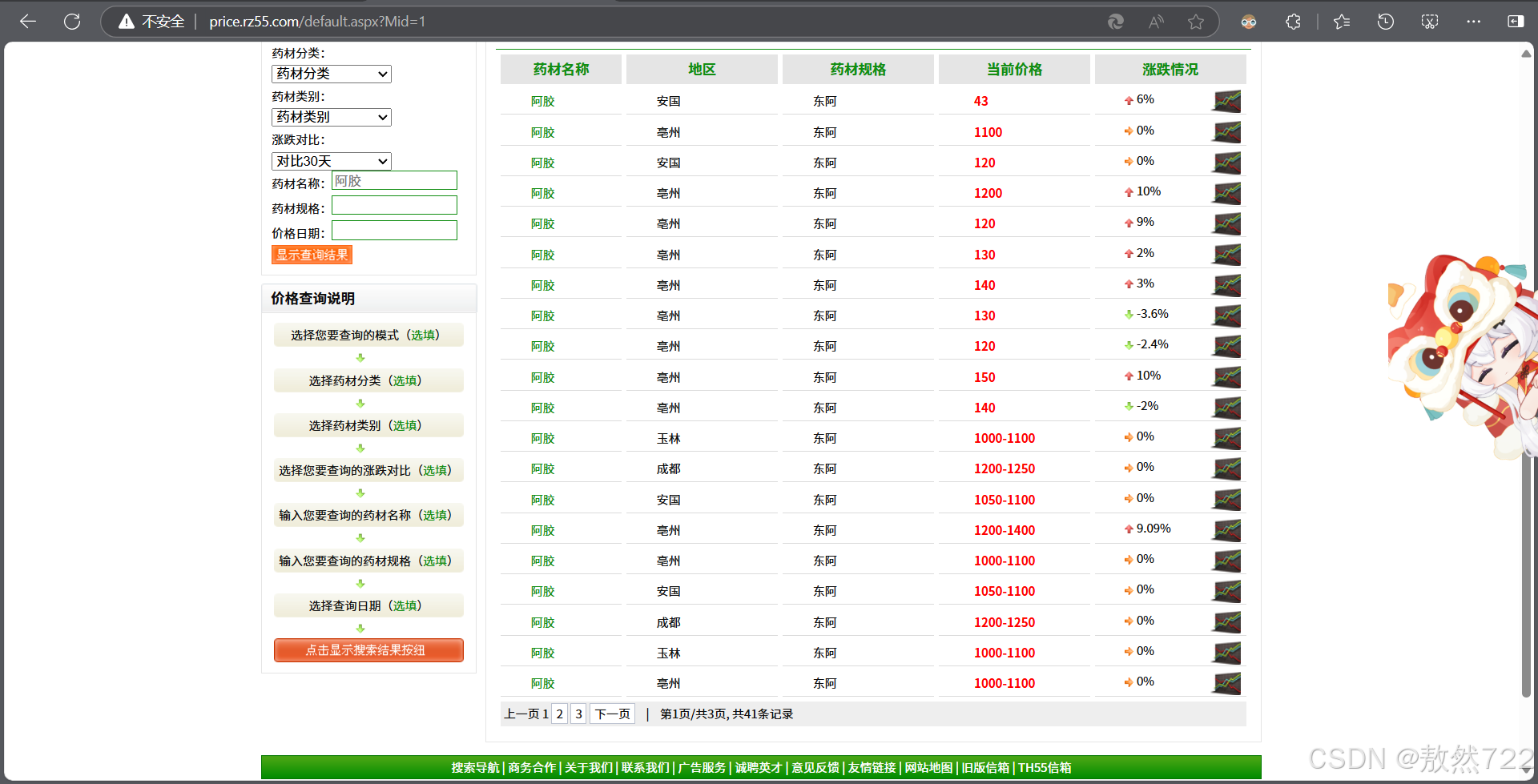
随便搜索药品阿胶,可以发现,网页页面多了?Mid=1部分,把页面改成?Mid=2,变成了药物阿魏的界面,那么很明显了,每种药品都有一个对应编号的页面,我们在需要爬取药材价格的时候,只需要向药材对应编号的链接请求再进行处理就行了,接下来我们进入网站的开发者模式,分析如何提取需要数据。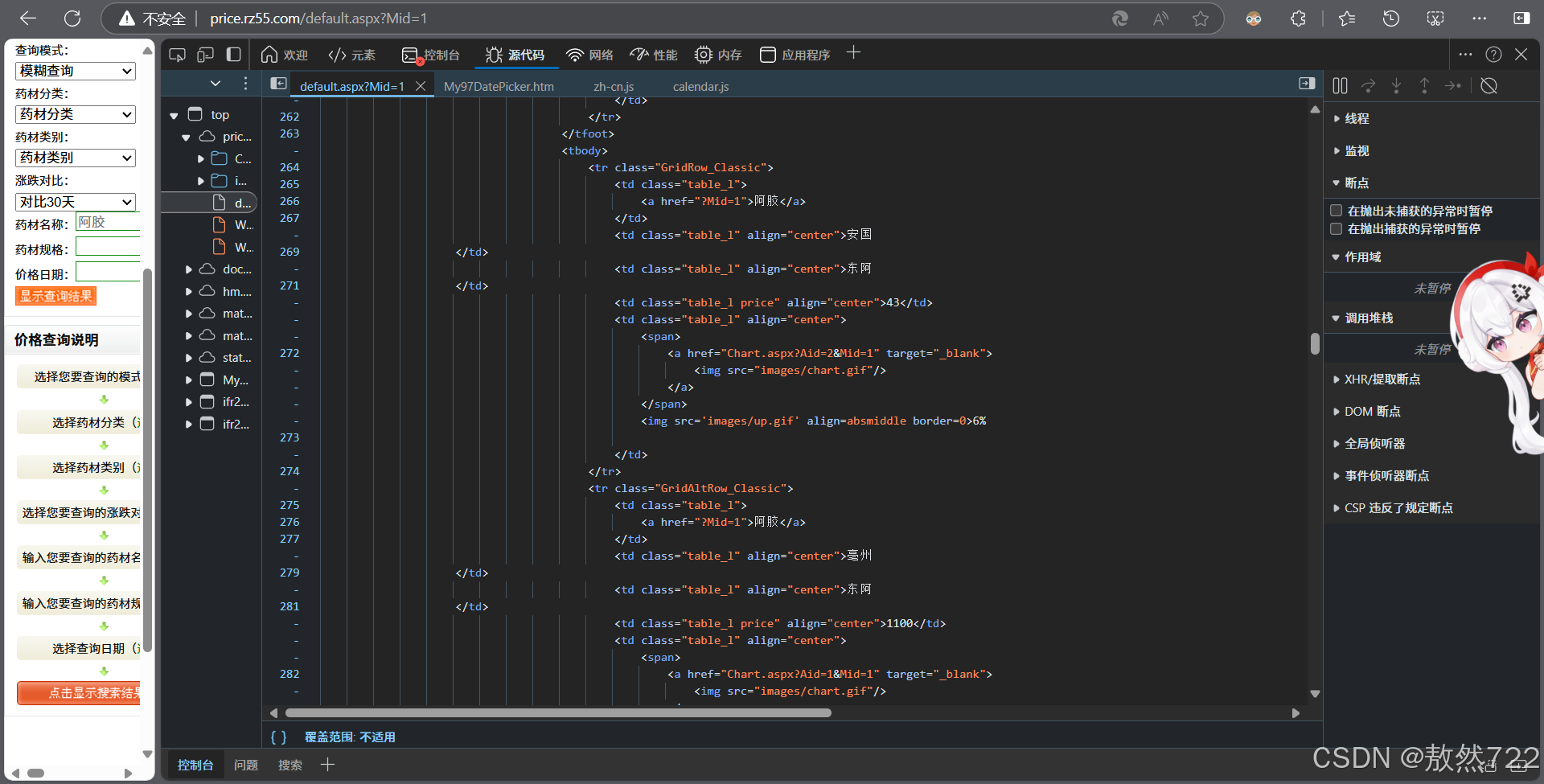
查看页面的源代码,可以发现药材名及其编号都在 <a href="?Mid=1">阿胶</a>这一标签中,那么我们在分析爬取到的内容时,首先提取所有的<a>标签,再提取所有<a>标签中带href和?Mid=的文本内容就行了,最后再将编号和对应的药材写入同一个文本文件即可。
程序编写
引入库
import requests
from bs4 import BeautifulSoup
import time引入这几个库,没什么好说的.
requests库用来发请求,获取网页内容。
BeautifulSoup库用来解析提取获取到的html内容。
time库用来设置时间间隔,避免对网站造成压力。
构造请求链接
def construct_url(base_url, number):
"""
构造请求的 URL
:param base_url: 基础 URL
:param number: 参数值
:return: 完整的 URL
"""
order = f"Mid={number}"
return f"{base_url}?{order}"我们不难发现我们访问的链接是由网站域名加?Mid=number组成的,每次爬取内容时对number进行自增操作,转换成字符型后再与域名拼接在一起再进行请求就行。
发送请求并解析html文件
def fetch_and_parse(url):
"""
发送请求并解析 HTML 内容
:param url: 请求的 URL
:return: BeautifulSoup 对象
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
return BeautifulSoup(response.text, 'html.parser')
except requests.RequestException as e:
print(f"请求出错: {e}")
except Exception as e:
print(f"发生其他错误: {e}")
return None在get请求中加入头文件,模拟成浏览器(试过了,不加会被拦截)
这一段代码很简单,没什么好说的。
提取标签
def extract_links(soup, number, printed_content, writer):
"""
提取符合条件的 <a> 标签文本内容,相同内容只输出一次,并以药品,编号数字的形式写入 CSV 文件,同时保留 print 输出
:param soup: BeautifulSoup 对象
:param number: 当前请求的 number
:param printed_content: 已输出内容的集合
:param writer: CSV 文件写入器对象
"""
if soup:
source_tag = soup.find_all('a')
for a_tag in source_tag:
href = a_tag.get('href')
if href and href.startswith('?Mid='):
text = a_tag.get_text()
if text not in printed_content:
output = f"{text},{number}"
print(output)
writer.writerow([text, number])
printed_content.add(text)思路在上边分析的时候已经说过了,很简单,先提取所有<a>标签。再找所有<a>标签以?Mid=开头的href,然后后续输出内容并以csv格式文件保存(方便提取的内容写入文件后续用csv库读取)
输出内容并写入文件
if __name__ == "__main__":
source_url = 'http://price.rz55.com/default.aspx'
# 用于记录已经输出过的内容
printed_content = set()
# 使用原始字符串表示路径
with open(r'E:Project FilesRepositoryPythonCrawleroutput1.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
# 修正拼写错误
writer.writerow(['herb', 'number'])
for number in range(1, 1200):
url = construct_url(source_url, number)
soup = fetch_and_parse(url)
extract_links(soup, number, printed_content, writer)
time.sleep(5)我这里写入的文件绝对路径是我的工作区的路径,自己用的时候改成自己的就行了。
并且为了防止网站压力过大,所以每5秒向网站请求一次,可以根据个人实际情况更改。
运行结果
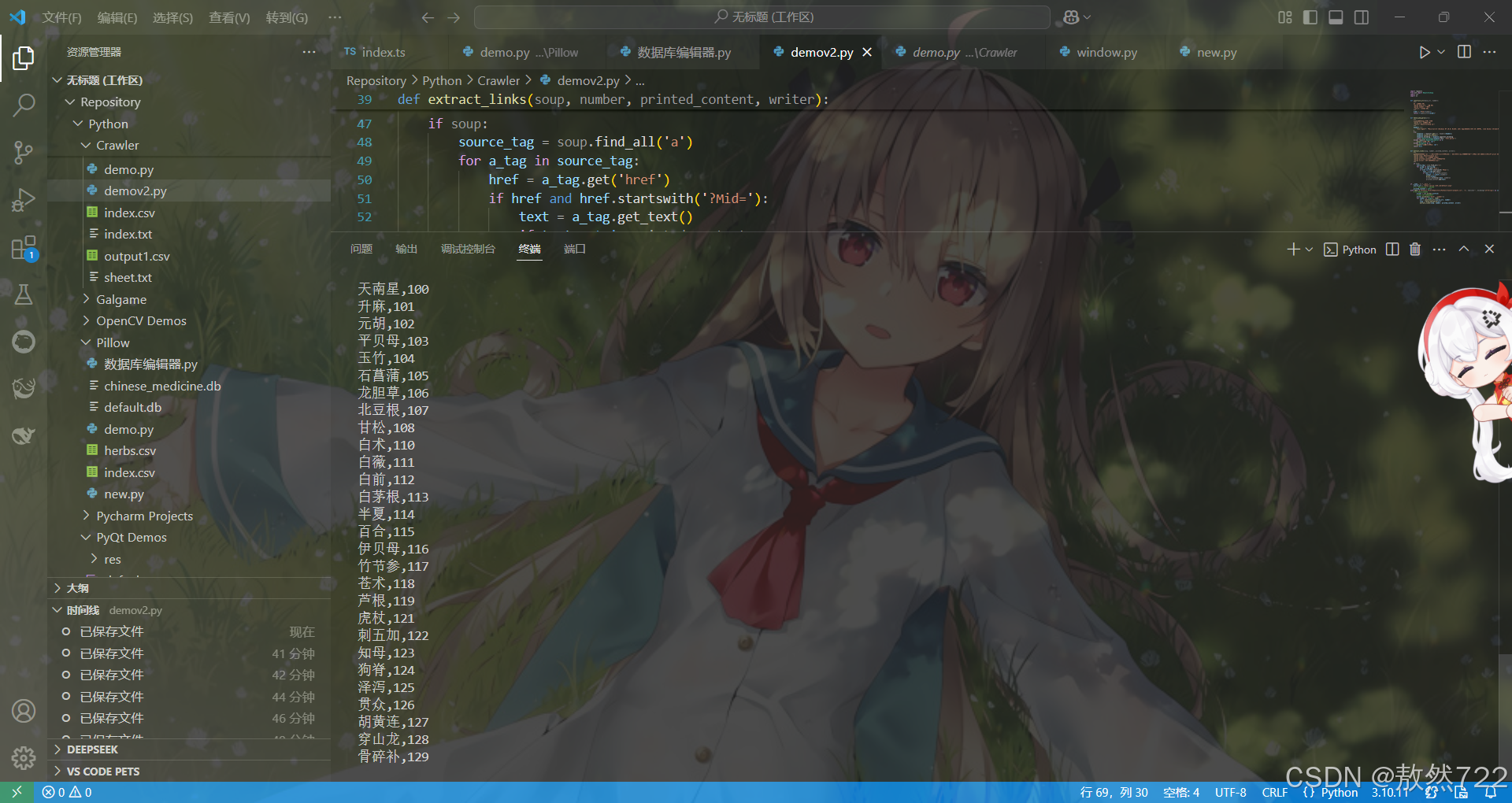
数据采集十分顺利,去重也做得很好,没有重复药材的情况,生成的.csv文件也一切正常,接下来就可以通过这个csv文件作为索引表再单独爬取各药材对应编号的链接就行了。
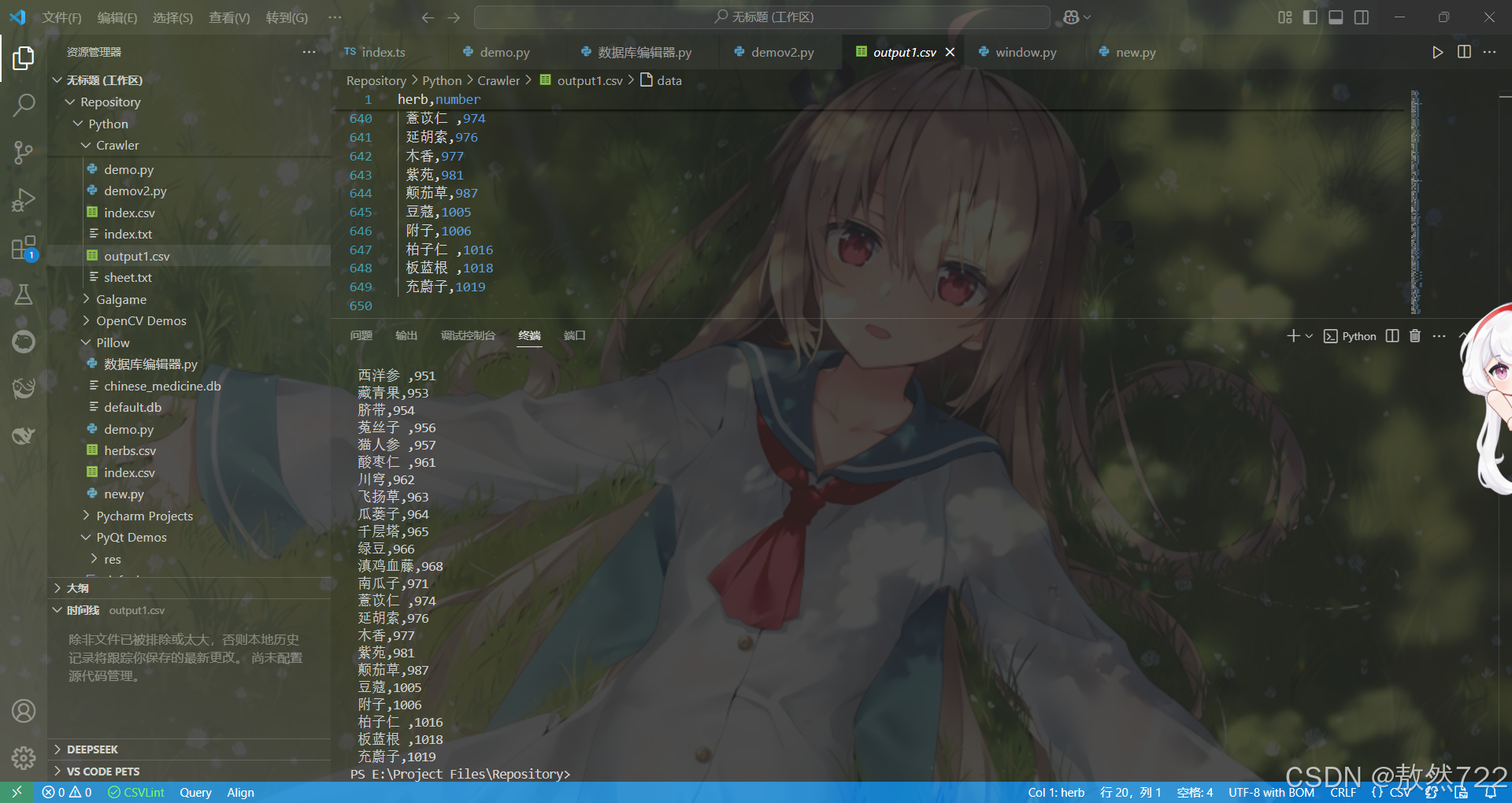
同样的思路可以应用到很多相仿的网站上,比如期货,首先获取所有种类对应的编号,后续在爬取实时价格时直接使用索引中对应的编号就行了。
完整代码
import requests
from bs4 import BeautifulSoup
import csv
import os
def construct_url(base_url, number):
"""
构造请求的 URL
:param base_url: 基础 URL
:param number: 参数值
:return: 完整的 URL
"""
order = f"Mid={number}"
return f"{base_url}?{order}"
def fetch_and_parse(url):
"""
发送请求并解析 HTML 内容
:param url: 请求的 URL
:return: BeautifulSoup 对象
"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
return BeautifulSoup(response.text, 'html.parser')
except requests.RequestException as e:
print(f"请求出错: {e}")
except Exception as e:
print(f"发生其他错误: {e}")
return None
def extract_links(soup, number, printed_content, writer):
"""
提取符合条件的 <a> 标签文本内容,相同内容只输出一次,并以药品,编号数字的形式写入 CSV 文件,同时保留 print 输出
:param soup: BeautifulSoup 对象
:param number: 当前请求的 number
:param printed_content: 已输出内容的集合
:param writer: CSV 文件写入器对象
"""
if soup:
source_tag = soup.find_all('a')
for a_tag in source_tag:
href = a_tag.get('href')
if href and href.startswith('?Mid='):
text = a_tag.get_text()
if text not in printed_content:
output = f"{text},{number}"
print(output)
writer.writerow([text, number])
printed_content.add(text)
if __name__ == "__main__":
source_url = 'http://price.rz55.com/default.aspx'
# 用于记录已经输出过的内容
printed_content = set()
with open('E:Project FilesRepositoryPythonCrawleroutput1.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
# 后续代码保持不变
writer = csv.writer(csvfile)
# 写入 CSV 文件的表头
writer.writerow(['herb', 'number'])
for number in range(1, 1200):
url = construct_url(source_url, number)
soup = fetch_and_parse(url)
extract_links(soup, number, printed_content, writer)





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结