您现在的位置是:首页 >技术杂谈 >Linux 内核自旋锁spinlock(二)--- ticket spinlock网站首页技术杂谈
Linux 内核自旋锁spinlock(二)--- ticket spinlock
前言
自旋锁是 Linux 内核中最底层的互斥机制。因此,它们对内核的安全性和性能有着巨大的影响,因此对各种(特定架构的)自旋锁实现进行了大量的优化工作并不奇怪。2.6.25 版本引入ticket spinlock。
在 x86 架构中,2.6.24 内核中的自旋锁由一个整数值表示。值为一表示锁是可用的。spin_lock() 函数的代码通过以系统范围的原子方式递减该值,然后查看结果是否为零来工作;如果是,则成功获取了锁。如果递减操作的结果为负数,spin_lock() 函数会知道该锁被其他线程占有。因此,它会在一个紧密的循环中忙等(“自旋”),直到锁的值变为正数;然后它会回到开头并再次尝试获取锁。
在关键部分执行完毕后,锁的所有者通过将其设置为1来释放锁。
这种实现非常快速,特别是在无争用情况下(大部分情况下应该是这样)。它还可以很容易地看出对锁的争用有多严重 - 锁的值越负,尝试获取它的处理器就越多。但是,这种方法存在一个缺点:它是不公平的。一旦释放锁,能够递减它的第一个处理器将成为新的所有者。无法确保等待时间最长的处理器首先获得锁;实际上,刚释放锁的处理器可能由于拥有该缓存行,在决定快速重新获取锁时具有优势。
一旦spinlock被释放,第一个能够成功执行CAS操作的CPU将成为新的owner,没有办法确保在该spinlock上等待时间最长的那个CPU优先获得锁,这将带来延迟不能确定的问题。
有可能存在多个线程同时争抢自旋锁的情况,但老版本的实现无法保证先抢的一定能先得到自旋锁。因此新版本(2.6.25以后)的实现排队功能,也就是先到先得。
因此Linux内核 2.6.25以后的的自旋锁 称为 ticket spinlock,基于 FIFO 算法的排队自选锁。
一、ticket spinlock
自旋锁变为16位量,分为两个字节:
next | owner
每个字节可以被视为一个票号(ticket)。比如在商店吃饭,在那里顾客拿着纸质票据以确保按到达顺序接受服务,你可以将“next”字段视为出现在取票机上下一张票上的号码,而“owner”是出现在柜台上“现在服务”的显示器上的号码。
比如:
(1)顾客A来时,next 和 owner都是0,next 等于 owner,说明锁没有被持有,可以加锁,此时饭店没有客人,顾客A的排号是0,直接进餐,同事next++,next = 1 。
(2)顾客B来时,next = 1 owner = 0,next 不等于 owner,说明锁被持有,此时饭店有客人在用餐,顾客B的排号是1,等待进餐,同事next++,next = 2 。
(3)顾客A吃完,owner++,owner = 1,此时顾客B的排号是1,owner = 顾客B的排号,因此顾客B用餐。
因此,在这个方案中,锁的值(两个字段)被初始化为零。spin_lock()函数首先注意到锁的值,然后递增“next”字段 - 所有操作都在单个原子操作中完成。如果“next”字段的值(在递增之前)等于“owner”,则已经获取了锁,工作可以继续进行。否则,处理器将自旋,等待直到“owner”递增到正确的值。在这个方案中,释放锁只需要简单地递增“owner”字段。
在旧的自旋锁实现中,所有争夺锁的处理器都争先恐后地抢夺锁。现在它们很好地排队等候,并按到达顺序获取锁。多线程运行时间变得更加平稳,最大延迟降低了(而且更重要的是,变得确定性)。

不同的架构以及内核版本字段稍有差异,owner对应图中 current_ticket,next对应图中 next_ticket。

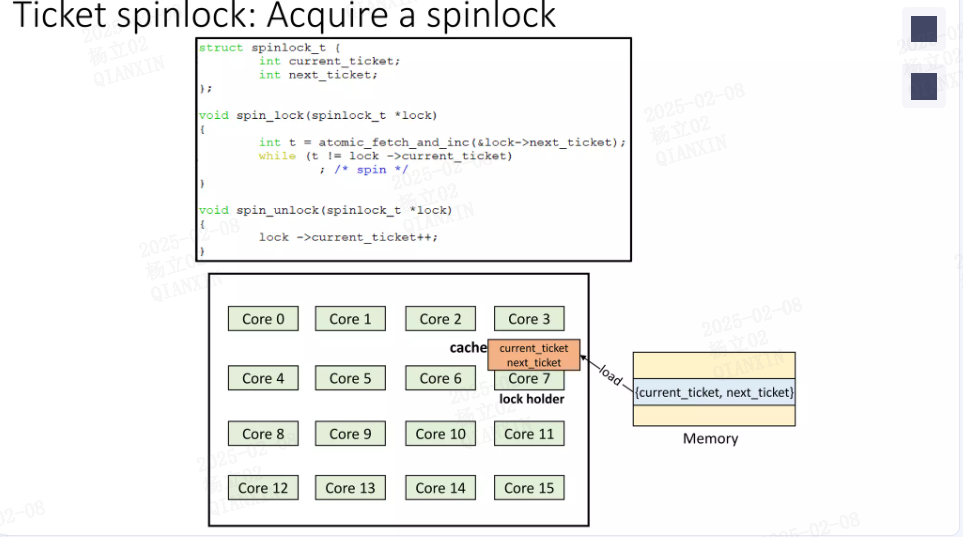
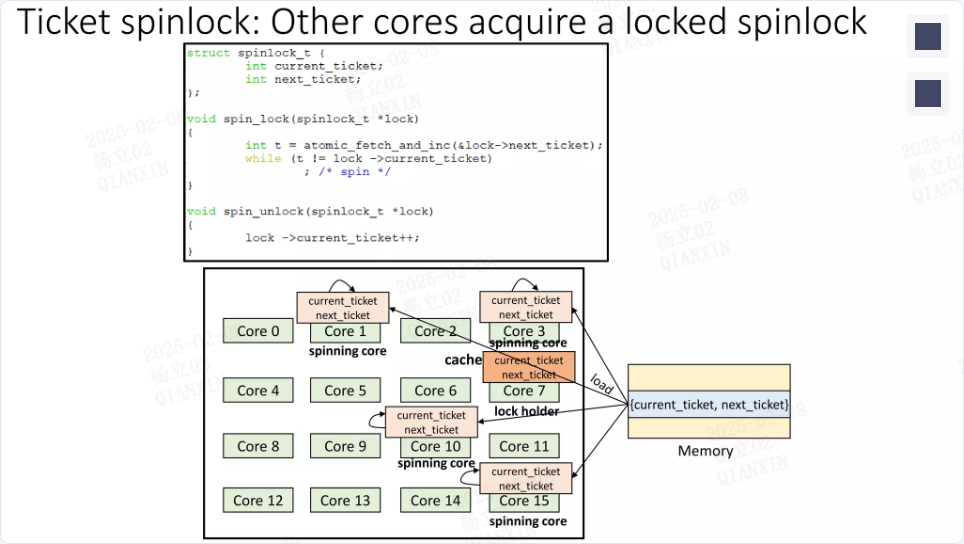
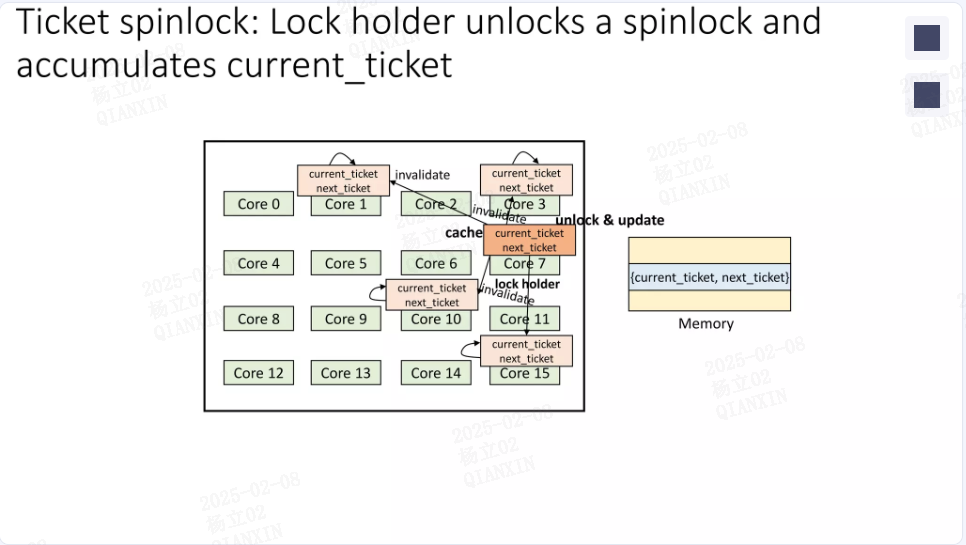
由于大多数自旋锁结构嵌入在属于同一缓存行的数据结构中,对缓存行进行一致性监控以读取当前头部或票据号会对锁持有者造成缓存丢失的不利影响。由于锁持有者以独占状态获取缓存行,因此由于多个线程读取当前头部位置或票据号的锁状态而导致缓存行的共享状态,会导致缓存行丢失。
可见,使用ticket spinlock可以让CPU按照到达的先后顺序,去获取spinlock的所有权,形成了「有序竞争」。根据硬件维护的cache一致性协议,如果spinlock的值没有更改,那么在busy wait时,试图获取spinlock的CPU,只需要不断地读取自己包含这个spinlock变量的cache line上的值就可以了,不需要从spinlock变量所在的内存位置读取。
但是,当spinlock的值被更改时,所有试图获取spinlock的CPU对应的cache line都会被invalidate,因为这些CPU会不停地读取这个spinlock的值,所以"invalidate"状态意味着此时,它们必须重新从内存读取新的spinlock的值到自己的cache line中。
而事实上,其中只会有一个CPU,也就是队列中最先达到的那个CPU,接下来可以获得spinlock,也只有它的cache line被invalidate才是有意义的,对于其他的CPU来说,这就是做无用功。内存比cache慢那么多,开销可不小。

在存在争用的锁的情况下,缓存争用似乎不是一个很大的问题。等待锁的 CPU 会以共享模式缓存其内容;直到拥有该锁的 CPU 释放它之前,不应该发生缓存跳动。释放锁(以及被另一个 CPU 获取)需要对锁进行写操作,这需要独占的缓存访问。那时的缓存行移动会造成损害,但可能不会像等待锁一样严重。因此,在存在争用的情况下,似乎尝试优化缓存行为不太可能产生太多有用的结果。
然而,这个情况并不完全;还必须考虑另外几个事实。处理器不会缓存单个值;它们会将连续的 128 个字节(通常)作为单个单位缓存为一个“行”。换句话说,在任何现代处理器中,缓存行几乎肯定比保存自旋锁所需的更大。因此,当一个 CPU 需要对自旋锁的缓存行进行独占访问时,它还会获得对周围大量数据的独占访问。这就是另一个重要细节的作用所在:自旋锁往往嵌入在它们保护的数据结构内部,因此周围的数据通常是持有锁的 CPU 感兴趣的数据。
内核代码会获取一个锁来处理(通常是修改)结构的内容。通常,修改受保护结构内的字段需要访问保存结构自旋锁的同一缓存行。如果锁没有争用,这种访问不是问题;拥有锁的 CPU 可能也拥有缓存行。但是,如果锁受到争用,将会有一个或多个其他 CPU 不断查询其值,获取对同一缓存行的共享访问,并剥夺锁持有者所需的独占访问。因此,在受影响的缓存行内的数据后续修改将导致缓存丢失。因此,查询受争用锁的 CPU 可以显著减慢锁持有者的速度,即使该持有者并未直接访问锁。
二、源码分析
typedef struct arch_spinlock {
union {
__ticketpair_t head_tail;
struct __raw_tickets {
__ticket_t head, tail;
} tickets;
};
} arch_spinlock_t;
简化成:
typedef struct arch_spinlock {
struct __raw_tickets {
__ticket_t head, tail;
} tickets;
} arch_spinlock_t;
head 和 tail 也就是 owner 和 next ,排队自旋锁的原理很简单,就是判断head和tail两个变量的值,如果相等则为未加锁,否则说明已经处于加锁状态。自旋锁初始化将head和tail都设置为0。当有线程加锁的时候,首先判断head和tail是否相等,相等就将tail加1,此时加锁成功。如果两者不相等则表示已经有其它线程加锁,此时只能等待。释放锁就将head加1。
2.1 spin_lock_init
// v3.10/source/include/linux/spinlock.h
#define spin_lock_init(_lock)
do {
spinlock_check(_lock);
raw_spin_lock_init(&(_lock)->rlock);
} while (0)
// v3.10/source/include/linux/spinlock.h
# define raw_spin_lock_init(lock)
do { *(lock) = __RAW_SPIN_LOCK_UNLOCKED(lock); } while (0)
// v3.10/source/include/linux/spinlock_types.h
#define __RAW_SPIN_LOCK_INITIALIZER(lockname)
{
.raw_lock = __ARCH_SPIN_LOCK_UNLOCKED,
SPIN_DEBUG_INIT(lockname)
SPIN_DEP_MAP_INIT(lockname) }
#define __RAW_SPIN_LOCK_UNLOCKED(lockname)
(raw_spinlock_t) __RAW_SPIN_LOCK_INITIALIZER(lockname)
// v3.10/source/arch/x86/include/asm/spinlock_types.h
#define __ARCH_SPIN_LOCK_UNLOCKED { { 0 } }
自旋锁初始化将head和tail都设置为0。
2.2 spin_lock
// v3.10/source/include/linux/spinlock.h
static inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
// v3.10/source/include/linux/spinlock.h
#define raw_spin_lock(lock) _raw_spin_lock(lock)
// v3.10/source/kernel/spinlock.c
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
// v3.10/source/include/linux/spinlock_api_smp.h
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
// v3.10/source/include/linux/spinlock.h
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
}
// v3.10/source/arch/x86/include/asm/spinlock.h
static __always_inline void arch_spin_lock(arch_spinlock_t *lock)
{
__ticket_spin_lock(lock);
}
// v3.10/source/arch/x86/include/asm/spinlock.h
/*
* Ticket locks are conceptually two parts, one indicating the current head of
* the queue, and the other indicating the current tail. The lock is acquired
* by atomically noting the tail and incrementing it by one (thus adding
* ourself to the queue and noting our position), then waiting until the head
* becomes equal to the the initial value of the tail.
*
* We use an xadd covering *both* parts of the lock, to increment the tail and
* also load the position of the head, which takes care of memory ordering
* issues and should be optimal for the uncontended case. Note the tail must be
* in the high part, because a wide xadd increment of the low part would carry
* up and contaminate the high part.
*/
static __always_inline void __ticket_spin_lock(arch_spinlock_t *lock)
{
register struct __raw_tickets inc = { .tail = 1 };
inc = xadd(&lock->tickets, inc);
for (;;) {
if (inc.head == inc.tail)
break;
cpu_relax();
inc.head = ACCESS_ONCE(lock->tickets.head);
}
barrier(); /* make sure nothing creeps before the lock is taken */
}
typedef struct arch_spinlock {
union {
__ticketpair_t head_tail;
struct __raw_tickets {
__ticket_t head, tail;
} tickets;
};
} arch_spinlock_t;
typedef struct arch_spinlock {
struct __raw_tickets {
__ticket_t head, tail;
} tickets;
} arch_spinlock_t;
核心思想
票证锁通过两个计数器(head 和 tail)实现公平的锁机制,保证线程按请求顺序获取锁(类似排队叫号系统)。
(1)tail:表示下一个可分配的“排队号”(线程获取锁时自增)。
(2)head:表示当前允许持有锁的“排队号”。
线程需等待直到自己的号(tail)与 head 相等才能获得锁。
票据锁由当前队列头部和尾部两部分构成。通过原子操作,首先注意到尾部并将其递增一,从而将自己添加到队列并记录位置,然后等待直到头部变为尾部的初始值。
(1)首先,创建一个名为 inc 的结构体 __raw_tickets,并将其初始化为 { .tail = 1 }。
使用 xadd 函数来原子地递增锁的票据数,并将其赋值给 inc。xadd 操作同时覆盖了锁的两个部分,即增加尾部并加载头部的位置,处理了内存排序问题。
inc = xadd(&lock->tickets, inc);
/*
* An exchange-type operation, which takes a value and a pointer, and
* returns the old value.
*/
#define __xchg_op(ptr, arg, op, lock)
({
__typeof__ (*(ptr)) __ret = (arg);
switch (sizeof(*(ptr))) {
case __X86_CASE_B:
asm volatile (lock #op "b %b0, %1
"
: "+q" (__ret), "+m" (*(ptr))
: : "memory", "cc");
break;
case __X86_CASE_W:
asm volatile (lock #op "w %w0, %1
"
: "+r" (__ret), "+m" (*(ptr))
: : "memory", "cc");
break;
case __X86_CASE_L:
asm volatile (lock #op "l %0, %1
"
: "+r" (__ret), "+m" (*(ptr))
: : "memory", "cc");
break;
case __X86_CASE_Q:
asm volatile (lock #op "q %q0, %1
"
: "+r" (__ret), "+m" (*(ptr))
: : "memory", "cc");
break;
default:
__ ## op ## _wrong_size();
}
__ret;
})
#define __xadd(ptr, inc, lock) __xchg_op((ptr), (inc), xadd, lock)
#define xadd(ptr, inc) __xadd((ptr), (inc), LOCK_PREFIX)
注意 xadd 返回的是旧值,而不是xadd后的新值。
xadd 是一个原子操作(Exchange & Add),初始化时 lock->tickets.tail = lock->tickets.head = 0,完成两件事:
原子地将 inc.tail(即 1)加到 lock->tickets.tail,相当于为当前线程分配一个“排队号”。
返回操作前的 lock->tickets 旧值(包含旧的 head = 0 和 tail = 0)。
执行后:
inc.tail 变为当前线程的“排队号”(旧 tail 值) = 0。
inc.head 被设为旧 head 值 = 0。
注释提到 tail 必须放在结构体的高位(如 64 位的高 32 位),因为 xadd 对低位的原子操作可能进位污染高位。例如,32 位的 xadd 操作低 16 位时,进位会影响高 16 位。
(2)然后,进入一个无限循环,检查 inc.head 是否等于 inc.tail,如果相等则跳出循环。如果不相等,则循环,在循环中,调用 cpu_relax 函数,然后将 inc.head 更新为 lock->tickets.head 的值。这个步骤是为了等待直到头部变为尾部的初始值。
循环条件:检查当前线程的“排队号”(inc.tail)是否等于当前 head。
若相等(inc.head == inc.tail),表示轮到当前线程持有锁,退出循环。
若不相等,继续等待。
cpu_relax():提示 CPU 减少自旋等待的能耗(如执行 pause 指令),避免总线争用。
/* REP NOP (PAUSE) is a good thing to insert into busy-wait loops. */
static inline void rep_nop(void)
{
__asm__ __volatile__("rep;nop": : :"memory");
}
#define cpu_relax() rep_nop()
示例流程
假设初始时 head=0, tail=0:
线程A 调用锁:
xadd 后 tail=1,返回旧值 head=0, tail=0 → inc.head=0, inc.tail=0。
检查 inc.head == inc.tail(0 == 0),直接获得锁。
线程B 调用锁:
xadd 后 tail=2,返回旧值 head=0, tail=1 → inc.head=0, inc.tail=1。
自旋等待直到 head 变为 1。
线程A 释放锁:
将 head 从 0 增到 1。
线程B 发现 head=1 与 inc.tail=1 相等,获得锁。
2.2 spin_unlock
// v3.10/source/include/linux/spinlock.h
static inline void spin_unlock(spinlock_t *lock)
{
raw_spin_unlock(&lock->rlock);
}
// /v3.10/source/include/linux/spinlock.h
#define raw_spin_unlock(lock) _raw_spin_unlock(lock)
// v3.10/source/kernel/spinlock.c
void __lockfunc _raw_spin_unlock(raw_spinlock_t *lock)
{
__raw_spin_unlock(lock);
}
// v3.10/source/include/linux/spinlock_api_smp.h
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, 1, _RET_IP_);
do_raw_spin_unlock(lock);
preempt_enable();
}
static inline void do_raw_spin_unlock(raw_spinlock_t *lock) __releases(lock)
{
arch_spin_unlock(&lock->raw_lock);
__release(lock);
}
// v3.10/source/arch/x86/include/asm/spinlock.h
static __always_inline void arch_spin_unlock(arch_spinlock_t *lock)
{
__ticket_spin_unlock(lock);
}
// v3.10/source/arch/x86/include/asm/spinlock.h
static __always_inline void __ticket_spin_unlock(arch_spinlock_t *lock)
{
__add(&lock->tickets.head, 1, UNLOCK_LOCK_PREFIX);
}
在函数中,使用 __add 函数对 lock->tickets.head 执行加1操作,以解锁该自旋锁。这段代码简单地对票据自旋锁进行解锁操作,通过增加 lock->tickets.head 的值来释放锁。
参考资料
https://lwn.net/Articles/267968/
https://zhuanlan.zhihu.com/p/62363777
http://www.wowotech.net/kernel_synchronization/spinlock.html
https://zhuanlan.zhihu.com/p/80727111
https://www.cnblogs.com/lovemengx/p/16989679.html






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结