您现在的位置是:首页 >其他 >图形引擎实战:Unity移动端带宽优化分享网站首页其他
图形引擎实战:Unity移动端带宽优化分享
在实际开发中,项目往往由于美术的天马行空和美术资源规范的遗漏导致带宽占用在不知不觉中超过了大多数移动端设备的极限,直到游戏运行几分钟就发热烫手后才意识到问题。本文将从实战经验出发,深入探讨如何对移动端设备进行带宽优化。
1.相关工具介绍
在开始性能优化之前,我们首先需要一个可靠的工具来帮助发现问题。高通的骁龙性能分析器(Snapdragon Profiler,简称SDP)正是这样一款强大的工具。SDP能够采集骁龙系列芯片的实机性能数据,包括GPU的读写总量、纹理内存占用、L1/L2缓存未命中率、时钟频率等关键指标,并提供实时(Realtime)和快照(Snapshot)两种工作模式。 在实际应用中,我们通常使用实时模式来监测游戏各项指标的变化情况,例如观察战斗场景下的带宽占用,以便定位异常场景。而快照模式则用于分析渲染管线中每个DrawCall的具体数据,从而找出异常项。值得注意的是,在真机测试时,如果使用Release版本,Snapshot只能获取指令级别的数据;而使用Debug版本则可以还原完整的渲染管线。另外,关于时钟频率的测量,SDP的数据并不够准确,建议使用XCode进行测量以获得更精确的结果。
2.带宽性能优化
2.1 减少Blit次数
通用渲染管线(URP)的新版本引入了一种先进的缓冲区管理机制——SwapBufferSystem。该系统通过实现A/B双缓冲策略,有效优化了后处理渲染流程。其核心是维护两个在渲染过程中交替使用的渲染目标缓冲区:
class RenderTargetBufferSystem{
struct SwapBuffer{
public RenderTargetHandle rt;
public int name;
public int msaa;
}
SwapBuffer m_A, m_B;
//......
}在早期版本中,后处理效果需要在临时缓冲区之间频繁地搬运数据,就像在两个仓库之间不断往返运送货物一样耗时耗力。而SwapBufferSystem的引入让整个流程变得高效——通过在两个缓冲区之间直接交替处理,避免了中间环节的重复拷贝操作。
static Dictionary<Vector2, RenderTargetBufferSystem> m_ColorBufferSystems = new();
static Dictionary<Vector2, RenderTargetHandle> m_CameraDepthAttachments = new();此外,为了支持我们项目中场景渲染与UI渲染采用不同分辨率的特性,我们需要对渲染管线进行进一步改造。具体做法是建立不同分辨率与相应RenderTargetBufferSystem的映射关系,并在主渲染相机分辨率发生变化时,及时清理多余的渲染目标,以避免长期占用内存。
同时,新的SwapBufferSystem还需要适配overlay类型的UI相机,因为否则overlay相机的后处理效果将无法使用SwapBuffer机制。完成适配后,系统可以在同一帧内缓存不同分辨率的ColorSwapBuffer和DepthAttachment。只有当base相机的分辨率发生变化时,系统才会清空缓存并重新绑定所有分辨率的RT。
// Setup
if (m_BaseCamerasResolution != m_CurrResolution){
m_BaseCamerasResolution = m_CurrResolution;
m_NeedClear = true;
}
// FinishRendering
if (m_NeedClear){
m_ColorBufferSystems.Clear();
m_CameraDepthAttachments.Clear();
m_NeedClear = false;
}在Unity的Android平台设置中,Unity提供了一个关键选项——BlitType,它决定了游戏画面最终呈现在玩家设备上的渲染方式。该选项提供了三种模式:
1.Always模式类似于画家先在草稿纸上创作,然后将完成的作品转移到画布上。这种方式虽然多了一道转换过程,但具有最佳的兼容性和适应性。
2.Never模式则直接在最终画布上进行创作,省去了中间环节。这种方式效率最高,但存在一定局限。例如,Never模式不提供sRGB后备缓冲区,在线性渲染工作流下会导致画面偏暗,开发者需要自行处理sRGB渲染目标和Blit操作。
3.Auto模式是一种自动选择的方式。 需要注意的是,当调用API将渲染结果写入设备的Backbuffer时,实际并非直接写入,硬件往往会额外执行一次Blit操作。启用Never模式可以减少这一次Blit的开销。 通过上述优化,我们成功为项目减少了两次不必要的Blit操作,显著降低了带宽占用。根据不同机型和场景负载情况,这两次Blit操作的带宽开销约为每帧8-15MB。
2.2 Bloom算法优化
传统Bloom效果的实现通常包含三个关键步骤:
1.亮度提取:根据预设阈值,计算像素灰度值并提取图像亮部
2.降采样与模糊:对亮部图像进行降采样,同时应用高斯模糊(为优化性能,常采用两次一维高斯模糊)
3.上采样混合:通过逐级上采样并加权混合,将图像恢复至原始分辨率,混合参数可用于调节最终效果(如光晕强度)
从论文《The Power of Box Filters》获得启发,我们可以对传统实现进行优化。该论文的核心思想是使用盒型滤波金字塔来逼近高斯滤波,这与Bloom效果的降采样-升采样流程不谋而合。具体而言,我们可以省略降采样过程中的高斯模糊操作,转而在升采样阶段通过特定的加权混合公式来获得等效的模糊效果。
TEXTURE2D_X(_MipUpLowTex);
float4 _MipUpLowTex_TexelSize;
float _MipSigma = 2.0;
uint _MipLevel;
uint _MipCount;
float MipGaussianBlendWeight(float2 uv){
const float sigma2 = sigma * sigma;
const float c = 4.0 * PI * sigma2;
const float numerator = (1 << (g_level << 2)) * log(4.0);
const float denorminator = c * ((1 << (g_level << 1)) + c);
return saturate(numerator / denorminator);
}
half4 FragUpsampleOpt(Varyings input) : SV_Target{
const float3 src = SAMPLE_TEXTURE2D_X_LOD(_MainTex, sampler_LinearClamp, input.uv, _MipLevel);
const float3 coarser = SAMPLE_TEXTURE2D_X(_MipUpLowTex, sampler_LinearClamp, input.uv);
const float weight = MipGaussianBlendWeight(input.uv, _MipSigma, _MipLevel, _MipCount);
return float4(lerp(coarser, src, weight), 1.0);
}在降采样金字塔的实现中,我们选择了单张启用mipmaps的纹理来替代传统的纹理数组方案。借助Unity提供的use mipmap接口,我们能够通过硬件生成mipmap来加速这一过程。
一些文章提出Unity的mipmap生成是基于compute shader实现的,一些文章则表示AMD和Nvidia开源的compute shader性能超过了硬件,但考虑到移动端对compute shader的支持度较差,往往只能通过pixel shader来模拟实现。所以我们通过RenderDoc截帧,想验证下到底是如何生成的mipmap。最终我们发现RenderDoc的截帧信息中只有一条generate mipmap指令。尽管本文没有对两种方案进行详细的性能对比,但从理论角度来看,采用硬件算法的单指令方案应该比多次blit具有更好的性能表现。
void SetupBloomOpt(CommandBuffer cmd, RenderTargetIdentifier source, Material uberMaterial){
// ......
var desc1 = GetStereoCompatibleDescriptor(tw, th, m_DefaultHDRFormat);
cmd.GetTemporaryRT(ShaderConstants._BloomOptMipUp[0], desc1, FilterMode.Bilinear);
var desc2 = desc1;
desc2.useMipMap = true;
desc2.autoGenerateMips = true;
cmd.GetTemporaryRT(ShaderConstants._BloomOptMipDown, desc2, FilterMode.Bilinear);
for (int i = 1; i < mipCount; i++){
tw = (int)Mathf.Max(1, tw / m_Bloom.downSample.value);
th = (int)Mathf.Max(1, th / m_Bloom.downSample.value);
desc1.width = tw;
desc1.height = th;
cmd.GetTemporaryRT(ShaderConstants._BloomOptMipUp[i], desc1, FilterMode.Bilinear);
}
cmd.SetGlobalTexture("_BlitTex", source);
cmd.Blit(source, ShaderConstants._BloomOptMipDown, bloomOptMaterial, 0);
cmd.SetGlobalInt(ShaderConstants._MipLevel, mipCount - 1);
cmd.Blit(ShaderConstants._BloomOptMipDown, ShaderConstants._BloomOptMipUp[mipCount - 1], bloomOptMaterial, 5);
cmd.SetGlobalInt(ShaderConstants._MipCount, mipCount);
cmd.SetGlobalFloat(ShaderConstants._MipSigma, m_Bloom.sigma.value);
for (int i = mipCount - 2; i >= 0; i--){
cmd.SetGlobalInt(ShaderConstants._MipLevel, i);
int low = ShaderConstants._BloomOptMipUp[i + 1];
int high = ShaderConstants._BloomOptMipUp[i];
cmd.SetGlobalTexture(ShaderConstants._MipUpLowTex, low);
cmd.Blit(ShaderConstants._BloomOptMipDown, high, bloomOptMaterial, 4);
}
// ......
}经过美术团队的专业评估,确认这种优化后的Bloom算法适用于非极致画质场景。左图为优化前,右图为优化后的效果。
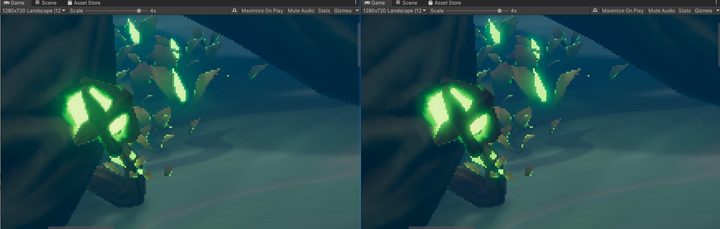
性能测试数据表明,优化后的Bloom算法可以减少1-2MB的带宽占用。结合前文提到的去除两次Blit操作,渲染管线的纹理带宽占用从46.20MB/帧降低至38.35MB/帧,总体降幅达17%。

2.3 纹理和模型优化
我们通过Snapdragon Profiler进行性能分析,发现项目存在严重的带宽使用问题。将数据与某同类型热门游戏进行对比:
参考游戏的性能数据:
-
纹理读带宽:平均0.7GB/s,峰值0.79GB/s
-
顶点读带宽:平均0.69GB/s,峰值1GB/s 本项目的初始数据:
-
纹理读带宽:平均2GB/s,峰值3GB/s
-
顶点读带宽:平均0.55GB/s,峰值0.93GB/s
更值得关注的是,在高端机型上测试同样场景时,纹理读取峰值达到3GB/s,而在内存性能较差的机型上甚至可达4GB/s。考虑到中端机型的总读写带宽峰值通常应控制在3GB/s以下,这些数据明显已经超出了合理范围。
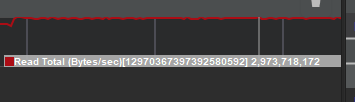
添加图片注释,不超过 140 字(可选)
更为严峻的问题是,当带宽接近设备极限时会引发连锁反应:原本仅需3-5MB/帧带宽的Blit操作,在极限负载情况下会急剧攀升至7-10MB/帧以上。
以下两张图对比展示了:
-
原始后处理的带宽占用(MB/帧)
-
剔除一次Blit操作并降低整体负载后的后处理带宽占用 这一对比清晰地说明了带宽压力与实际性能消耗之间的关联性。


通过分析,我们发现部分模型DrawCall的L1/L2 Texture Cache未命中率异常偏高,达到了40%-70%,而正常水平应该在30%左右。经过排查,这些纹理存在一个共同特点:UV利用率较低,这种情况通常是由资产复用或不当的合批处理导致。 值得注意的是,即使采用最简单的优化方式——将UV合理铺满贴图,就能显著降低带宽占用。

噪声图的texture cache miss率也非常高,每个实例都要占据500-600KB/帧的带宽。

我们还发现噪声图的texture cache未命中率也异常偏高,每个实例都会消耗500-600KB/帧的带宽。此外,大面积重复纹理(如地板)虽然占据了大量像素,却会导致cache利用率升高。而当纹理中存在透明或半透明像素时,在TBDR架构下还会触发另一个问题:需要将Tile从系统内存中的FrameBuffer回读到片上缓存。 实际测试证明了优化的显著效果:仅通过重新展开某个UV利用率低的纹理,该场景的带宽峰值就从3GB/s下降至2.4GB/s。这个数据充分说明了UV展开对性能优化的重要性。
通过引擎中的UV利用率分析工具,我们指导美术团队对所有场景中UV利用率偏低的模型纹理进行重新展开。
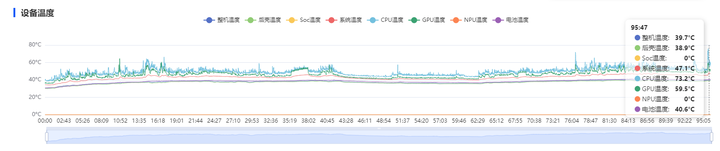
同时,借助Snapdragon Profiler定位并优化了精度过高的纹理和模型。这些优化措施取得了显著成效:大部分场景的总读带宽均值稳定在1.65GB/s左右,峰值控制在2GB/s附近;在1h的游玩下,测试设备的温度也维持40℃的理想水平。
3. 参考资料
欢迎加入我们!
感兴趣的同学可以投递简历至:CYouEngine@cyou-inc.com






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结