您现在的位置是:首页 >技术教程 >TingWebServer服务器代码解读02网站首页技术教程
TingWebServer服务器代码解读02
上一篇:TingWebServer服务器代码解读01
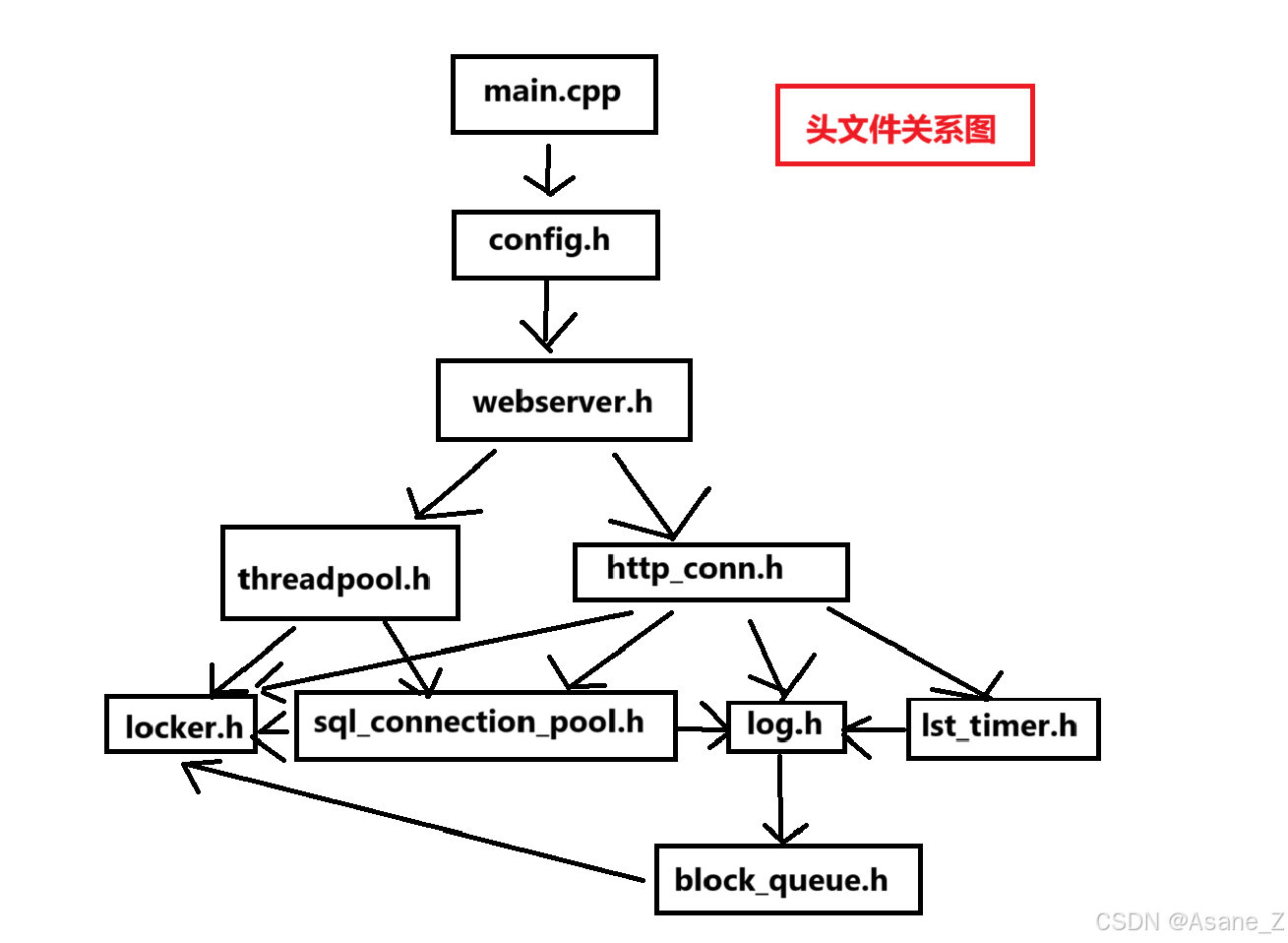
我们将跟随这个头文件包含图,继续逐级解读代码,我们解读的顺序还是从上往下的,这样能清楚的了解tingwebserver的服务器的框架包含结构,但在解读上一级文件的时候往往会运用到下一级的包含代码,因此希望读者在翻阅代码解读的时候多开几个窗口,以便在读到相关子集代码的时候能迅速找到对于代码解析。
这篇将进入TingWebserver的文件夹中解读相关文件,从thereadpool和http_conn.h解读到最后的日志文件。
Threadpool文件夹
README:
半同步/半反应堆线程池
使用一个工作队列完全解除了主线程和工作线程的耦合关系:主线程往工作队列中插入任务,工作线程通过竞争来取得任务并执行它。
- 同步I/O模拟proactor模式
- 半同步/半反应堆
- 线程池
threadpool.h
跳过头文件
线程池定义:
template <typename T>
class threadpool
{
public:
//构造函数,传参:工作模式,数据库连接池,线程数,最大请求量
threadpool(int actor_model, connection_pool *connPool, int thread_number = 8, int max_request = 10000);
~threadpool();
//把请求添加到工作队列当中
bool append(T *request, int state);
bool append_p(T *request);
private:
static void *worker(void *arg);
void run();
private:
int m_thread_number; // 线程池中的线程数
int m_max_requests; // 请求队列中允许的最大请求数
pthread_t *m_threads; // 线程池的线程数组
std::list<T *> m_workqueue; // 请求队列,存储待处理的请求
locker m_queuelocker; // 保护请求队列的互斥锁
sem m_queuestat; // 信号量,表示请求队列中的任务数量
connection_pool *m_connPool; // 数据库连接池
int m_actor_model; // 工作模型,支持不同的请求处理模式
};
构造函数:threadpool
- 初始化参数:构造函数接收参数来设置线程池的大小、请求队列的最大容量、工作模型以及数据库连接池。
- 线程池创建:首先检查线程数和最大请求数是否合法,如果不合法则抛出异常。然后为线程池分配内存并创建线程。每个线程会运行
worker函数,并传递this指针作为参数。 - 线程分离:使用
pthread_detach来分离线程,这样每个线程结束后会自动释放资源,而不需要手动join。 std::list<T *> m_workqueue存储的是任务对象的指针,这样可以避免对象的拷贝,并且能够更好地管理对象的生命周期
template <typename T>
threadpool<T>::threadpool(int actor_model, connection_pool *connPool, int thread_number, int max_requests)
: m_actor_model(actor_model), m_thread_number(thread_number), m_max_requests(max_requests), m_threads(NULL), m_connPool(connPool)
//类内成员初始化
{
if (thread_number <= 0 || max_requests <= 0)
throw std::exception(); // 如果线程数或最大请求数不合法,抛出异常
m_threads = new pthread_t[m_thread_number]; // 创建线程池
if (!m_threads)
throw std::exception();
// 创建工作线程
for (int i = 0; i < thread_number; ++i)
{
if (pthread_create(m_threads + i, NULL, worker, this) != 0)
{
delete[] m_threads;
throw std::exception(); // 创建线程失败,抛出异常
}
if (pthread_detach(m_threads[i])) // 分离线程
{
delete[] m_threads;
throw std::exception(); // 分离线程失败,抛出异常
}
}
}
析构函数 :~threadpool
template <typename T>
threadpool<T>::~threadpool()
{
delete[] m_threads; // 释放线程池的内存
}
任务队列操作:append 和 append_p
template <typename T>
bool threadpool<T>::append(T *request, int state)
{
m_queuelocker.lock();//先加锁,再操作
if (m_workqueue.size() >= m_max_requests) // 如果请求队列已满,返回 false
{
m_queuelocker.unlock();
return false;
}
request->m_state = state; // 设置请求的状态
m_workqueue.push_back(request); // 将请求添加到队列
m_queuelocker.unlock();//结束操作,解锁
m_queuestat.post(); // 通知有新的请求
return true;
}
append_p是一个不用state参数的加入请求队列函数
template <typename T>
bool threadpool<T>::append_p(T *request)
{
m_queuelocker.lock();
if (m_workqueue.size() >= m_max_requests) // 如果请求队列已满,返回 false
{
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back(request); // 将请求添加到队列
m_queuelocker.unlock();
m_queuestat.post(); // 通知有新的请求
return true;
}
工作线程:worker 和 run
在多线程编程中,线程的执行函数(即线程入口函数)必须是一个符合操作系统要求的格式。在 POSIX 线程(pthread)中,线程入口函数的原型是:
void* thread_func(void* arg);
直接使用run函数,因为run函数没有传入参数void*,所以创建一个中介函数worker,将传递给线程的参数从void*转化为threadpool*类型,从而可以调用run函数,上面的pthread_create传入了this(本线程),当作worker的传入参数void*arg,从而调用pool的run函数
worker函数:
template <typename T>
void *threadpool<T>::worker(void *arg)
{
threadpool *pool = (threadpool *)arg;
pool->run(); // 每个线程调用 run 函数
return pool;
}
run函数:
进入循环,然后信号m_queuestat进行阻塞直到有新任务,上锁,判断队列是否为空,是则解锁继续等待,否则进行处理,获取第一个请求,(在wait到了信号后,进行 m_queuestat内部的信号处理,m_wirkqueue队列+1),读取请求后移除,进行解锁,然后根据不同的操作模式进行不同的操作
Reactor 模式:当
m_actor_model为 1 时,表示线程池采用的是 Reactor 模式。
读取请求:如果请求的状态
request->m_state为 0,表示该请求是读取操作。此时,调用request->read_once()读取数据:
- 如果读取成功,则设置
request->improv = 1,表示请求已被改进,接着创建一个connectionRAII对象来管理数据库连接,最后调用request->process()处理请求。- 如果读取失败,设置
request->timer_flag = 1,表示该请求读取失败,需要设置定时器进行超时处理。写入请求:如果请求的状态是写入操作(
request->m_state为 1),调用request->write()写入数据:
- 如果写入成功,设置
request->improv = 1。- 如果写入失败,设置
request->timer_flag = 1,表示写入失败,需要进行超时处理
Proactor 模式:当
m_actor_model不为 1 时,表示线程池采用的是 Proactor 模式。
在 Proactor 模式下,线程池会直接从请求队列中取出请求并进行处理。
connectionRAII是用于管理数据库连接的智能指针,确保数据库连接在请求处理完后自动释放。然后调用
request->process()处理请求。
template <typename T>
void threadpool<T>::run()
{
while (true)//进行循环
{
m_queuestat.wait(); // 等待任务
m_queuelocker.lock();//上锁
if (m_workqueue.empty()) // 如果请求队列为空,则继续等待
{
m_queuelocker.unlock();
continue;
}
T *request = m_workqueue.front(); // 获取队列中的第一个请求
m_workqueue.pop_front(); // 从队列中移除请求
m_queuelocker.unlock();
//如果请求为空,跳过当前循环进入下一次,防止程序崩溃
if (!request)
continue;
// 根据 actor_model 选择不同的处理方式
if (1 == m_actor_model) // Reactor 模式
{
if (0 == request->m_state) // 读取请求
{
if (request->read_once()) // 读取成功
{
request->improv = 1; // 设置请求改为改进状态
connectionRAII mysqlcon(&request->mysql, m_connPool); // 获取数据库连接
request->process(); // 处理请求
}
else
{
request->improv = 1;
request->timer_flag = 1; // 请求读取失败,设置超时标志
}
}
else // 写入请求
{
if (request->write()) // 写入成功
{
request->improv = 1;
}
else
{
request->improv = 1;
request->timer_flag = 1; // 请求写入失败,设置超时标志
}
}
}
else // Proactor 模式
{
connectionRAII mysqlcon(&request->mysql, m_connPool);
request->process(); // 处理请求
}
}
}
Http文件夹
README:
http连接处理类
根据状态转移,通过主从状态机封装了http连接类。其中,主状态机在内部调用从状态机,从状态机将处理状态和数据传给主状态机
- 客户端发出http连接请求
- 从状态机读取数据,更新自身状态和接收数据,传给主状态机
- 主状态机根据从状态机状态,更新自身状态,决定响应请求还是继续读取
http_conn.h
#ifndef HTTPCONNECTION_H
#define HTTPCONNECTION_H
// 包含头文件,提供系统调用、网络功能和其他操作所需的库
#include <unistd.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/epoll.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <sys/stat.h>
#include <string.h>
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <stdarg.h>
#include <errno.h>
#include <sys/wait.h>
#include <sys/uio.h>
#include <map>
#include "../lock/locker.h" // 锁的操作
#include "../CGImysql/sql_connection_pool.h" // MySQL连接池
#include "../timer/lst_timer.h" // 定时器
#include "../log/log.h" // 日志管理
class http_conn
{
public:
// 定义常量
static const int FILENAME_LEN = 200; // 文件名最大长度
static const int READ_BUFFER_SIZE = 2048; // 读缓冲区大小
static const int WRITE_BUFFER_SIZE = 1024; // 写缓冲区大小
// HTTP请求的方法
enum METHOD
{
GET = 0,
POST,
HEAD,
PUT,
DELETE,
TRACE,
OPTIONS,
CONNECT,
PATH
};
// 检查请求的不同状态
enum CHECK_STATE
{
CHECK_STATE_REQUESTLINE = 0, // 请求行检查状态
CHECK_STATE_HEADER, // 请求头检查状态
CHECK_STATE_CONTENT // 请求内容检查状态
};
// HTTP状态码
enum HTTP_CODE
{
NO_REQUEST, // 没有请求
GET_REQUEST, // GET 请求
BAD_REQUEST, // 错误请求
NO_RESOURCE, // 无资源
FORBIDDEN_REQUEST, // 禁止请求
FILE_REQUEST, // 文件请求
INTERNAL_ERROR, // 内部错误
CLOSED_CONNECTION // 关闭连接
};
// 行的解析状态
enum LINE_STATUS
{
LINE_OK = 0, // 行格式正确
LINE_BAD, // 行格式错误
LINE_OPEN // 行未完全接收
};
public:
http_conn() {} // 构造函数
~http_conn() {} // 析构函数
public:
// 初始化 HTTP 连接
void init(int sockfd, const sockaddr_in &addr, char *root, int trigmode, int close_log, string user, string passwd, string sqlname);
// 关闭连接
void close_conn(bool real_close = true);
// 处理请求
void process();
// 读取请求数据
bool read_once();
// 写响应数据
bool write();
// 获取客户端的地址
sockaddr_in *get_address()
{
return &m_address;
}
// 初始化数据库连接
void initmysql_result(connection_pool *connPool);
// 定时器标志和改进标志
int timer_flag;
int improv;
private:
// 内部初始化函数
void init();
// 处理读取请求的函数
HTTP_CODE process_read();
// 处理写入响应的函数
bool process_write(HTTP_CODE ret);
// 解析请求行
HTTP_CODE parse_request_line(char *text);
// 解析请求头
HTTP_CODE parse_headers(char *text);
// 解析请求内容
HTTP_CODE parse_content(char *text);
// 执行请求
HTTP_CODE do_request();
// 获取当前行的指针
char *get_line() { return m_read_buf + m_start_line; };
// 解析一行数据
LINE_STATUS parse_line();
// 解除内存映射
void unmap();
// 添加响应头
bool add_response(const char *format, ...);
// 添加响应内容
bool add_content(const char *content);
// 添加状态行
bool add_status_line(int status, const char *title);
// 添加响应头
bool add_headers(int content_length);
// 添加内容类型
bool add_content_type();
// 添加内容长度
bool add_content_length(int content_length);
// 添加连接状态
bool add_linger();
// 添加空行
bool add_blank_line();
public:
// 静态成员变量,所有 http_conn 对象共享
static int m_epollfd; // epoll 文件描述符,用于事件通知
static int m_user_count; // 当前连接的用户数
MYSQL *mysql; // MySQL 数据库连接
int m_state; // 请求的状态(读为 0,写为 1)
private:
int m_sockfd; // 客户端 socket 文件描述符
sockaddr_in m_address; // 客户端地址信息
char m_read_buf[READ_BUFFER_SIZE]; // 读缓冲区
long m_read_idx; // 当前读取到缓冲区的字节数
long m_checked_idx; // 已检查的字节数
int m_start_line; // 当前行的起始位置
char m_write_buf[WRITE_BUFFER_SIZE]; // 写缓冲区
int m_write_idx; // 当前写入的字节数
CHECK_STATE m_check_state; // 当前请求的检查状态
METHOD m_method; // 请求方法(GET、POST等)
char m_real_file[FILENAME_LEN]; // 请求的文件路径
char *m_url; // 请求的URL
char *m_version; // HTTP版本
char *m_host; // Host头
long m_content_length; // 内容长度
bool m_linger; // 是否保持连接
char *m_file_address; // 文件内存地址
struct stat m_file_stat; // 文件状态
struct iovec m_iv[2]; // 用于writev的写缓冲区
int m_iv_count; // 写缓冲区数量
int cgi; // 是否启用POST方法
char *m_string; // 存储请求头数据
int bytes_to_send; // 要发送的字节数
int bytes_have_send; // 已发送的字节数
char *doc_root; // 网站根目录
// 存储用户信息的map
map<string, string> m_users;
// 配置相关
int m_TRIGMode; // 触发模式
int m_close_log; // 是否关闭日志
// 数据库连接的配置信息
char sql_user[100];
char sql_passwd[100];
char sql_name[100];
};
#endif
常量定义:
FILENAME_LEN:文件名最大长度。READ_BUFFER_SIZE:读取缓冲区大小。WRITE_BUFFER_SIZE:写入缓冲区大小。枚举类型:
METHOD:HTTP请求方法类型(如 GET、POST、DELETE 等)。CHECK_STATE:HTTP请求的检查状态(请求行、请求头、请求内容)。HTTP_CODE:HTTP响应代码(如 NO_REQUEST, GET_REQUEST, BAD_REQUEST 等)。LINE_STATUS:解析请求行时的状态。函数:
init():初始化HTTP连接,绑定文件描述符和客户端地址等。close_conn():关闭连接,释放相关资源。process():处理请求,负责请求的读取、解析、响应等。read_once():从客户端读取请求数据。write():向客户端写入响应数据。MySQL相关:
initmysql_result():初始化MySQL连接。m_users:用于存储用户信息。文件相关:
m_real_file:存储文件的路径名。m_file_stat:存储文件的状态信息。定时器和触发模式:
timer_flag:定时器标志,用于判断是否需要关闭连接。m_TRIGMode:触发模式(如边缘触发或水平触发)。
http_conn.cpp
头文件以及宏定义
#include "http_conn.h"
#include <mysql/mysql.h>
#include <fstream>
// 定义 HTTP 响应的一些状态信息
const char *ok_200_title = "OK"; // 状态码 200 的响应标题
const char *error_400_title = "Bad Request"; // 状态码 400 的响应标题
const char *error_400_form = "Your request has bad syntax or is inherently impossible to satisfy.
"; // 状态码 400 错误信息
const char *error_403_title = "Forbidden"; // 状态码 403 的响应标题
const char *error_403_form = "You do not have permission to get file from this server.
"; // 状态码 403 错误信息
const char *error_404_title = "Not Found"; // 状态码 404 的响应标题
const char *error_404_form = "The requested file was not found on this server.
"; // 状态码 404 错误信息
const char *error_500_title = "Internal Error"; // 状态码 500 的响应标题
const char *error_500_form = "There was an unusual problem serving the request file.
"; // 状态码 500 错误信息
获取数据库信息函数:initmysql_result
把数据库中保存的user和password映射倒map中,map的结构为:
map<string, string> users;string 类型的 key 表示用户名,value 表示密码。这样就可以通过用户名在 users map 中查找对应的密码,从而实现简单的用户验证机制
connectionRAII mysqlcon(&mysql, connPool)是一个栈对象,它的构造函数会从数据库连接池connPool中获取一个 MySQL 连接,并将其赋值给mysql。connectionRAII可能是一个自定义的 RAII(资源获取即初始化)类,确保在作用域结束时自动释放数据库连接。
mysql_query是 MySQL C API 中的函数,用于执行 SQL 查询。它执行查询"SELECT username,passwd FROM user",即从user表中选择username和passwd字段
mysql_store_result(mysql)获取查询结果并返回MYSQL_RES类型的指针result。这个指针指向存储了 SQL 查询结果的结构体。
mysql_num_fields(result)返回结果集中的字段(列)数,即user表中的列数。
mysql_fetch_fields(result)返回一个MYSQL_FIELD数组,包含每个字段的元数据(例如字段名、数据类型等)。
mysql_fetch_row(result)从结果集中获取一行数据,返回一个MYSQL_ROW类型的指针,row是一个包含字段值的数组。
row[0]是当前行的第一个字段,即username。row[1]是当前行的第二个字段,即passwd。- 通过
string构造函数将username和passwd转换为string类型的temp1和temp2。- 使用
users[temp1] = temp2;将username作为key,passwd作为value存入全局的usersmap。
void http_conn::initmysql_result(connection_pool *connPool)
{
//先从连接池中取一个连接
MYSQL *mysql = NULL;
connectionRAII mysqlcon(&mysql, connPool);
//在user表中检索username,passwd数据,浏览器端输入
if (mysql_query(mysql, "SELECT username,passwd FROM user"))
{
LOG_ERROR("SELECT error:%s
", mysql_error(mysql));
}
//从表中检索完整的结果集
MYSQL_RES *result = mysql_store_result(mysql);
//返回结果集中的列数
int num_fields = mysql_num_fields(result);
//返回所有字段结构的数组
MYSQL_FIELD *fields = mysql_fetch_fields(result);
//从结果集中获取下一行,将对应的用户名和密码,存入map中
while (MYSQL_ROW row = mysql_fetch_row(result))
{
string temp1(row[0]);
string temp2(row[1]);
users[temp1] = temp2;
}
}文件描述符设置非阻塞函数:setnonblocking
设置非阻塞
//对文件描述符设置非阻塞
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}注册读事件函数:addfd
//将内核事件表注册读事件,ET模式,选择开启EPOLLONESHOT
void addfd(int epollfd, int fd, bool one_shot, int TRIGMode)
{
epoll_event event;
event.data.fd = fd;
if (1 == TRIGMode)//根据trig模式设置为ET或者LT触发模式
event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;//ET
else
event.events = EPOLLIN | EPOLLRDHUP;//LT
if (one_shot)//选择开启oneshot
event.events |= EPOLLONESHOT;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);//挂上红黑树
setnonblocking(fd);//设置非阻塞
}删除文件描述符:removefd
//从内核时间表删除描述符
void removefd(int epollfd, int fd)
{
epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0);
close(fd);
}事件重置为EPOLLONESHOT函数:modfd
不同触发模式不同event
void modfd(int epollfd, int fd, int ev, int TRIGMode)
{
epoll_event event;
event.data.fd = fd;
if (1 == TRIGMode)
event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
else
event.events = ev | EPOLLONESHOT | EPOLLRDHUP;
epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event);
}类外初始化静态变量:
int http_conn::m_user_count = 0;
int http_conn::m_epollfd = -1;
m_user_count用于记录当前活动的http_conn实例的数量:连接的用户数。
m_epollfd是与 epoll 相关的文件描述符,通常用于处理 I/O 多路复用。-1是一个常用的表示未初始化或出错的标志。
关闭连接函数:close_conn
void http_conn::close_conn(bool real_close)//real_close表示是否需要执行关闭操作
{
if (real_close && (m_sockfd != -1))//m_sockfd != -1表示当前套接字是否有效
{
printf("close %d
", m_sockfd);
removefd(m_epollfd, m_sockfd);//移除文件描述符
m_sockfd = -1;//表示连接关闭
m_user_count--;//连接数量-1
}
}初始化连接函数:init
初始化一个新的http连接对象 ,把套接字和地址传给成员变量,调用addfd将当前套接字加到epoll实例中去,增加活跃连接数,配置网站根目录、触发模式、日志标志、数据库连接信息等,调用 init 函数完成其他内部初始化工作。
void http_conn::init(int sockfd, const sockaddr_in &addr, char *root, int TRIGMode,
int close_log, string user, string passwd, string sqlname)
{
m_sockfd = sockfd;
m_address = addr;
addfd(m_epollfd, sockfd, true, m_TRIGMode);//注册读事件
m_user_count++;//连接数量+1
//当浏览器出现连接重置时,可能是网站根目录出错或http响应格式出错或者访问的文件中内容完全为空
doc_root = root;
m_TRIGMode = TRIGMode;
m_close_log = close_log;
strcpy(sql_user, user.c_str());
strcpy(sql_passwd, passwd.c_str());//passwd 赋值给成员变量 sql_passwd
strcpy(sql_name, sqlname.c_str());//sqlname 赋值给成员变量 sql_name
init();//下面的void init()进行剩下的初始化工作
}初始化新接受的连接:void init
作用于前面的init中
// HTTP连接的初始化函数,设置所有与HTTP请求相关的成员变量的初始状态
void http_conn::init()
{
mysql = NULL; // 将MySQL连接指针初始化为NULL,表示尚未连接到数据库
bytes_to_send = 0; // 设置待发送的字节数为0
bytes_have_send = 0; // 设置已发送的字节数为0
m_check_state = CHECK_STATE_REQUESTLINE; // 设置解析状态机的初始状态为请求行分析状态
m_linger = false; // 设置HTTP请求不使用长连接(默认为短连接)
m_method = GET; // 默认为GET方法
m_url = 0; // 设置URL为NULL,表示没有设置请求的URL
m_version = 0; // 设置HTTP版本为NULL,表示未指定HTTP版本
m_content_length = 0; // 设置内容长度为0
m_host = 0; // 设置Host字段为NULL
m_start_line = 0; // 请求行的起始位置为0
m_checked_idx = 0; // 当前分析的字符位置为0
m_read_idx = 0; // 当前读取的字节位置为0
m_write_idx = 0; // 当前写入的字节位置为0
cgi = 0; // 默认不启用CGI功能(如POST请求)
m_state = 0; // 请求的状态初始化为0
timer_flag = 0; // 定时器标志初始化为0,表示没有定时器标记
improv = 0; // 改进标志初始化为0,表示没有改进状态
memset(m_read_buf, '�', READ_BUFFER_SIZE); // 清空读取缓存区,将其初始化为全零
memset(m_write_buf, '�', WRITE_BUFFER_SIZE); // 清空写入缓存区,将其初始化为全零
memset(m_real_file, '�', FILENAME_LEN); // 清空存储真实文件路径的字符数组
}
分析行函数:parse_line
parse_line()函数的作用是从m_read_buf缓冲区中逐字符检查一行数据,并确保该行符合HTTP协议的格式(每行以结尾)。- 如果符合格式,返回
LINE_OK;如果格式错误,返回LINE_BAD;如果没有解析到完整的一行,返回LINE_OPEN。- 这个设计的目的是分步读取和检查HTTP请求的每一行,确保处理流程的严谨性。
char temp;
for (; m_checked_idx < m_read_idx; ++m_checked_idx)
{
temp = m_read_buf[m_checked_idx]; // 获取当前要检查的字符
if (temp == '
') // 检查是否遇到回车符 '
'
{
if ((m_checked_idx + 1) == m_read_idx) // 如果回车符后没有换行符,则当前行未结束
return LINE_OPEN; // 返回 LINE_OPEN,表示这一行没有结束,仍然在读取中
else if (m_read_buf[m_checked_idx + 1] == '
') // 如果回车符后紧跟着换行符 '
'
{
m_read_buf[m_checked_idx++] = '�'; // 将回车符 '
' 置为 '�',标记行结束
m_read_buf[m_checked_idx++] = '�'; // 将换行符 '
' 置为 '�',标记行结束
return LINE_OK; // 返回 LINE_OK,表示成功解析出完整的一行
}
return LINE_BAD; // 如果回车符后没有换行符,则返回 LINE_BAD,表示该行格式错误
}
else if (temp == '
') // 检查是否遇到换行符 '
'
{
if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '
') // 如果换行符前有回车符 '
'
{
m_read_buf[m_checked_idx - 1] = '�'; // 将回车符 '
' 置为 '�',标记行结束
m_read_buf[m_checked_idx++] = '�'; // 将换行符 '
' 置为 '�',标记行结束
return LINE_OK; // 返回 LINE_OK,表示成功解析出完整的一行
}
return LINE_BAD; // 如果没有回车符前缀,则返回 LINE_BAD,表示该行格式错误
}
}
return LINE_OPEN; // 如果没有找到回车换行符,则返回 LINE_OPEN,表示该行还未结束
读取数据函数:read_once
- LT 模式:
recv每次读取一次,读取的数据量有限,每次调用都会返回已读取的字节数。如果没有数据可读取,recv返回0或负数,函数根据返回值判断读取结果。- ET 模式:
recv尽可能多地读取数据,并且只有在没有更多数据时才停止。此模式适用于高效读取,在一次recv调用后没有数据时不会再继续触发读取,直到有数据到来。
bool http_conn::read_once()
{
if (m_read_idx >= READ_BUFFER_SIZE)//检查缓冲区是否已经填满
{
return false;
}
int bytes_read = 0;//记录本次读取字节数
//LT读取数据
if (0 == m_TRIGMode)
{
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);//m_read_buf + m_read_idx为本次数据存储下标
m_read_idx += bytes_read;//更新下标
if (bytes_read <= 0)//未读出数据
{
return false;
}
return true;
}
//ET读数据
else
{
while (true)//循环读取数据,直至没有
{
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);
if (bytes_read == -1)
{
if (errno == EAGAIN || errno == EWOULDBLOCK)//暂时没有可读取的数据,跳出进行下一次循环
break;
return false;//其他错误则返回读取失败
}
else if (bytes_read == 0)//连接关闭
{
return false;
}
m_read_idx += bytes_read;//更新下标
}
return true;
}
} 解析http请求行函数:parse_request_line
解析传入http请求头,假设传入的是 GET /index.html HTTP/1.1 ,函数是从其中取出 HTTP 方法(GET)、URL(/index.html)和版本(HTTP/1.1)
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{
m_url = strpbrk(text, " ");//返回第一个空格的位置
if (!m_url)
{
return BAD_REQUEST;
}
*m_url++ = '�';//将空格转化为字符串终止符'/0'
char *method = text;//mothod指向请求行开始
if (strcasecmp(method, "GET") == 0)//匹配请求字符
m_method = GET;
else if (strcasecmp(method, "POST") == 0)
{
m_method = POST;
cgi = 1;
}
else
return BAD_REQUEST;//说明请求的方法不支持
m_url += strspn(m_url, " ");//跳过前面的字符,开始http请求处理
m_version = strpbrk(m_url, " ");//查找第一个空格位置
if (!m_version)
return BAD_REQUEST;
*m_version++ = '�';
m_version += strspn(m_version, " ");
if (strcasecmp(m_version, "HTTP/1.1") != 0)
return BAD_REQUEST;
if (strncasecmp(m_url, "http://", 7) == 0)
{
m_url += 7;
m_url = strchr(m_url, '/');
}
if (strncasecmp(m_url, "https://", 8) == 0)
{
m_url += 8;
m_url = strchr(m_url, '/');
}
if (!m_url || m_url[0] != '/')
return BAD_REQUEST;
//当url为/时,显示判断界面
if (strlen(m_url) == 1)
strcat(m_url, "judge.html");
m_check_state = CHECK_STATE_HEADER;
return NO_REQUEST;
}解析http请求的头部信息函数:parse_headers:
传入的text是上面parse_line函数切割出来的每一行的内容
该函数接收一个指向 HTTP 头部字段的字符串
text,然后解析:
Connection头部(是否是keep-alive)Content-Length头部(请求体长度)Host头部(主机名)如果
text为空行,则意味着请求头解析结束:
- 如果
Content-Length不是 0,则说明请求有请求体,状态转换为CHECK_STATE_CONTENT- 否则,解析完成,返回
GET_REQUEST
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{
if (text[0] == '�')//读取到空行
{
if (m_content_length != 0)//请求带有请求体(post请求)
{
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
return GET_REQUEST;//get请求,直接返回表示请求完成
}
else if (strncasecmp(text, "Connection:", 11) == 0)
{
text += 11;
text += strspn(text, " ");
if (strcasecmp(text, "keep-alive") == 0)//表示HTTP是持久连接
{
m_linger = true;//表示连接不会立即关闭
}
}
else if (strncasecmp(text, "Content-length:", 15) == 0)//指定请求体长度,通常用于POST
{
text += 15;
text += strspn(text, " ");
m_content_length = atol(text);//字符串转化为long类型
}
else if (strncasecmp(text, "Host:", 5) == 0)//读入的是host
{
text += 5;
text += strspn(text, " ");
m_host = text;//主机名保留到变量中
}
else
{
LOG_INFO("oop!unknow header: %s", text);//其他信息
}
return NO_REQUEST;
}
判断http请求是否被完整读入函数:parse_conte
当读取长度大于等于请求体长度+http头部长度,判断为请求体完整,进行处理
http_conn::HTTP_CODE http_conn::parse_content(char *text)
{
if (m_read_idx >= (m_content_length + m_checked_idx))
{
text[m_content_length] = '�';//手动添加字符串终止符
//POST请求中最后为输入的用户名和密码
m_string = text;//把请求体的数据存入 m_string 变量
return GET_REQUEST;
}
return NO_REQUEST;
}解析http主体函数:process_read
process_read()是 HTTP 请求解析的核心,解析请求行、头部和请求体。- 使用
while循环不断解析,确保完整接收 HTTP 请求。 - 调用
parse_request_line()、parse_headers()、parse_content()进行解析。 - 请求完整时调用
do_request()处理请求,否则等待更多数据。
| 步骤 | m_check_state | text 解析内容 | ret 解析结果 | 下一步 |
|---|---|---|---|---|
| 1 | CHECK_STATE_REQUESTLINE | POST /login HTTP/1.1 | NO_REQUEST | 进入 CHECK_STATE_HEADER |
| 2 | CHECK_STATE_HEADER | Host: www.example.com | NO_REQUEST | 继续解析头部 |
| 3 | CHECK_STATE_HEADER | Content-Length: 15 | NO_REQUEST | 继续解析 |
| 4 | CHECK_STATE_HEADER | (空行,表示头部结束) | NO_REQUEST | 进入 CHECK_STATE_CONTENT |
| 5 | CHECK_STATE_CONTENT | user=admin&pwd=123 | GET_REQUEST | 调用 do_request() 处理 |
http_conn::HTTP_CODE http_conn::process_read()
{
LINE_STATUS line_status = LINE_OK; // 记录当前行解析状态
HTTP_CODE ret = NO_REQUEST; // 记录 HTTP 请求的解析状态
char *text = 0; // 存储当前解析的行文本
// 解析 HTTP 请求的所有行
while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK))
{
text = get_line(); // 获取当前行的起始地址
m_start_line = m_checked_idx;
LOG_INFO("%s", text); // 记录日志,输出当前解析的文本行
switch (m_check_state)
{
case CHECK_STATE_REQUESTLINE:
{
ret = parse_request_line(text); // 解析请求行
if (ret == BAD_REQUEST)
return BAD_REQUEST;
break;
}
case CHECK_STATE_HEADER:
{
ret = parse_headers(text); // 解析请求头
if (ret == BAD_REQUEST)
return BAD_REQUEST;
else if (ret == GET_REQUEST)
{
return do_request(); // 解析完成,调用 do_request() 处理请求
}
break;
}
case CHECK_STATE_CONTENT:
{
ret = parse_content(text); // 解析请求体
if (ret == GET_REQUEST)
return do_request();
line_status = LINE_OPEN; // 请求体可能不止一行,继续解析
break;
}
default:
return INTERNAL_ERROR; // 状态异常,返回服务器内部错误
}
}
return NO_REQUEST; // 如果解析未完成,则继续等待数据
}
处理静态文件请求和动态请求函数:do_request
- 动态请求处理: 如果是 登录 或 注册 请求,会提取
POST数据,执行数据库操作,返回不同的页面。- 静态资源处理: 解析 URL 和路径,根据不同的条件返回不同的静态页面。
- 文件操作: 在文件请求时,检查文件存在、权限以及是否为目录。符合条件则映射文件至内存,准备响应。
http_conn::HTTP_CODE http_conn::do_request()
{
strcpy(m_real_file, doc_root);
int len = strlen(doc_root);//设置文件实质路径
//printf("m_url:%s
", m_url);
const char *p = strrchr(m_url, '/');
//处理cgi
if (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3'))
{
//根据标志判断是登录检测还是注册检测
char flag = m_url[1];
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/");
strcat(m_url_real, m_url + 2);
strncpy(m_real_file + len, m_url_real, FILENAME_LEN - len - 1);
free(m_url_real);
//将用户名和密码提取出来
//user=123&passwd=123
char name[100], password[100];
int i;
for (i = 5; m_string[i] != '&'; ++i)
name[i - 5] = m_string[i];
name[i - 5] = '�';
int j = 0;
for (i = i + 10; m_string[i] != '�'; ++i, ++j)
password[j] = m_string[i];
password[j] = '�';
if (*(p + 1) == '3')
{
//如果是注册,先检测数据库中是否有重名的
//没有重名的,进行增加数据
char *sql_insert = (char *)malloc(sizeof(char) * 200);
strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES(");
strcat(sql_insert, "'");
strcat(sql_insert, name);
strcat(sql_insert, "', '");
strcat(sql_insert, password);
strcat(sql_insert, "')");
if (users.find(name) == users.end())
{
m_lock.lock();
int res = mysql_query(mysql, sql_insert);
users.insert(pair<string, string>(name, password));
m_lock.unlock();
if (!res)
strcpy(m_url, "/log.html");
else
strcpy(m_url, "/registerError.html");
}
else
strcpy(m_url, "/registerError.html");
}
//如果是登录,直接判断
//若浏览器端输入的用户名和密码在表中可以查找到,返回1,否则返回0
else if (*(p + 1) == '2')
{
if (users.find(name) != users.end() && users[name] == password)
strcpy(m_url, "/welcome.html");
else
strcpy(m_url, "/logError.html");
}
}
if (*(p + 1) == '0')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/register.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '1')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/log.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '5')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/picture.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '6')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/video.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else if (*(p + 1) == '7')
{
char *m_url_real = (char *)malloc(sizeof(char) * 200);
strcpy(m_url_real, "/fans.html");
strncpy(m_real_file + len, m_url_real, strlen(m_url_real));
free(m_url_real);
}
else
strncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);
if (stat(m_real_file, &m_file_stat) < 0)
return NO_RESOURCE;
if (!(m_file_stat.st_mode & S_IROTH))
return FORBIDDEN_REQUEST;
if (S_ISDIR(m_file_stat.st_mode))
return BAD_REQUEST;
int fd = open(m_real_file, O_RDONLY);
m_file_address = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
close(fd);
return FILE_REQUEST;
}解除内存映射函数:unmap
void http_conn::unmap()
{
if (m_file_address)
{
munmap(m_file_address, m_file_stat.st_size);// 解除内存映射
m_file_address = 0;// 清空文件地址
}
}发送http响应函数:write
bool http_conn::write()
{
int temp = 0;
// 如果没有数据要发送,修改 epoll 事件为 EPOLLIN,并初始化连接
if (bytes_to_send == 0)
{
modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode); // 修改 epoll 事件为 EPOLLIN(可读)
init(); // 重置连接状态
return true;
}
while (1)
{
// 使用 writev 系统调用将多个缓冲区的数据写入套接字
temp = writev(m_sockfd, m_iv, m_iv_count);
if (temp < 0)
{
// 如果写入时返回错误并且 errno 为 EAGAIN,表示当前缓冲区不可写(非阻塞)
if (errno == EAGAIN)
{
// 修改 epoll 事件为 EPOLLOUT(可写),表示稍后可以继续写
modfd(m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode);
return true;
}
// 如果发生其他错误,解除内存映射并返回失败
unmap();
return false;
}
// 更新已发送的字节数,并减少剩余要发送的字节数
bytes_have_send += temp;
bytes_to_send -= temp;
// 如果已经发送完了 m_iv[0] 缓冲区的内容
if (bytes_have_send >= m_iv[0].iov_len)
{
// 设置 m_iv[0] 不再需要写入
m_iv[0].iov_len = 0;
// 更新 m_iv[1] 为剩余的数据部分
m_iv[1].iov_base = m_file_address + (bytes_have_send - m_write_idx);
m_iv[1].iov_len = bytes_to_send;
}
else
{
// 否则继续写入 m_iv[0] 缓冲区剩余部分
m_iv[0].iov_base = m_write_buf + bytes_have_send;
m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;
}
// 如果所有数据都已经发送完
if (bytes_to_send <= 0)
{
unmap(); // 解除内存映射
// 修改 epoll 事件为 EPOLLIN(可以继续读取)
modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);
// 如果连接保持活动状态(HTTP/1.1),则继续处理后续请求
if (m_linger)
{
init(); // 重置连接状态
return true;
}
else
{
return false; // 关闭连接
}
}
}
}
缓冲区添加数据函数:add_response
通过 vsnprintf 处理可变参数,确保不会超出缓冲区的大小限制,并更新 m_write_idx 来记录写入的位置。如果添加成功,返回 true;如果失败(例如缓冲区不足以容纳数据),则返回 false
bool http_conn::add_response(const char *format, ...)
{
// 检查写缓冲区是否已经满
if (m_write_idx >= WRITE_BUFFER_SIZE)
return false;
va_list arg_list;
va_start(arg_list, format);
// 使用 vsnprintf 来格式化数据并写入 m_write_buf 中
int len = vsnprintf(m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list);
// 检查格式化后的长度是否超出了剩余的缓冲区大小
if (len >= (WRITE_BUFFER_SIZE - 1 - m_write_idx))
{
va_end(arg_list); // 结束可变参数的处理
return false; // 缓冲区空间不足,返回 false
}
// 更新写入数据的索引
m_write_idx += len;
va_end(arg_list); // 结束可变参数的处理
// 记录日志,记录请求的响应内容
LOG_INFO("request:%s", m_write_buf);
return true;
}
构造报文辅助函数合集
//构建并添加 HTTP 响应的状态行
bool http_conn::add_status_line(int status, const char *title)
{
return add_response("%s %d %s
", "HTTP/1.1", status, title);
}
//添加响应头部
bool http_conn::add_headers(int content_len)
{
return add_content_length(content_len) && add_linger() &&
add_blank_line();
}
//添加 Content-Length 响应头,指示响应体的长度
bool http_conn::add_content_length(int content_len)
{
return add_response("Content-Length:%d
", content_len);
}
//添加 Content-Type 响应头,指示响应体的类型
bool http_conn::add_content_type()
{
return add_response("Content-Type:%s
", "text/html");
}
//添加 Connection 响应头,指示客户端与服务器之间的连接是否持续
bool http_conn::add_linger()
{
return add_response("Connection:%s
", (m_linger == true) ? "keep-alive" : "close");
}
//添加一个空行,表示 HTTP 响应头的结束
bool http_conn::add_blank_line()
{
return add_response("%s", "
");
}
//添加响应体的内容
bool http_conn::add_content(const char *content)
{
return add_response("%s", content);
}构造响应报文函数:process_write
- 根据不同的
HTTP_CODE返回值(如INTERNAL_ERROR,BAD_REQUEST,FORBIDDEN_REQUEST,FILE_REQUEST)生成适当的响应内容。- 对于错误响应,函数会构建一个包含错误信息的页面并返回相应的 HTTP 状态码。
- 对于成功的文件请求,函数会构建一个包含文件内容的响应。
- 该函数通过调用
add_status_line()、add_headers()和add_content()等方法来填充响应报文的各个部分,并通过m_iv数组分块发送数据。
bool http_conn::process_write(HTTP_CODE ret)
{
switch (ret)
{
case INTERNAL_ERROR://当发生服务器内部错误时(状态码 500)
{
add_status_line(500, error_500_title);
add_headers(strlen(error_500_form));
if (!add_content(error_500_form))
return false;
break;
}
case BAD_REQUEST://当请求不合法时(状态码 400):
{
add_status_line(404, error_404_title);
add_headers(strlen(error_404_form));
if (!add_content(error_404_form))
return false;
break;
}
case FORBIDDEN_REQUEST://当访问被拒绝时(状态码 403):
{
add_status_line(403, error_403_title);
add_headers(strlen(error_403_form));
if (!add_content(error_403_form))
return false;
break;
}
case FILE_REQUEST://当请求成功并且服务器能够提供文件时(状态码 200):
{
add_status_line(200, ok_200_title);
if (m_file_stat.st_size != 0)
{
add_headers(m_file_stat.st_size);
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv[1].iov_base = m_file_address;
m_iv[1].iov_len = m_file_stat.st_size;
m_iv_count = 2;
bytes_to_send = m_write_idx + m_file_stat.st_size;
return true;
}
else
{
const char *ok_string = "<html><body></body></html>";
add_headers(strlen(ok_string));
if (!add_content(ok_string))
return false;
}
}
default:
return false;
}
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv_count = 1;
bytes_to_send = m_write_idx;
return true;
}http处理核心函数:process
- 函数的工作流程是:首先调用
process_read()来解析客户端的请求,如果请求还没有完成,就继续等待更多数据;如果请求已经完成,就通过process_write()生成响应并通过EPOLLOUT事件准备发送。- 它在接收到请求后决定是继续读取数据(通过
EPOLLIN)还是准备发送响应(通过EPOLLOUT)
void http_conn::process()
{
HTTP_CODE read_ret = process_read();// 读取和解析请求
if (read_ret == NO_REQUEST)//判断是否需要进一步处理请求
{
modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);
return;
}
bool write_ret = process_write(read_ret);// 处理请求并生成响应
if (!write_ret)
{
close_conn();
}
modfd(m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode);//修改事件类型为 EPOLLOUT,准备发送响应
}





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结