您现在的位置是:首页 >技术交流 >当ES与MySQL开始「异地恋」:大数据量同步方案全解析网站首页技术交流
当ES与MySQL开始「异地恋」:大数据量同步方案全解析
简介当ES与MySQL开始「异地恋」:大数据量同步方案全解析
当ES与MySQL开始「异地恋」:大数据量同步方案全解析

一、同步方案生存指南(为什么需要同步?)
MySQL是严谨的财务总监(ACID强迫症患者)
ES是夜店最靓的DJ(擅长花式查询的全文搜索引擎)
当结构化数据需要全文检索/聚合分析时,这对CP必须学会「双向奔赴」
二、同步方案大乱斗
方案1:双写直连(简单粗暴型)
// 伪代码示例:在业务代码里同时操作两个数据库
void createOrder(Order order) {
mysql.insert(order); // 正房必须宠幸
es.index(order); // 新欢也得安排
if(不一致) {
// 准备熬夜修数据吧(手动狗头)
}
}
优点:
- 实时性高(约等于网恋奔现的速度)
- 架构简单(代码界的直男操作)
缺点:
- 数据一致性薛定谔(网络波动:这个锅我背了)
- 业务强耦合(改业务代码像拆炸弹)
- 性能损耗明显(双倍写入,双倍快乐?)
适用场景:小规模业务(用户量还没突破三位数的初创公司)
方案2:Binlog同步(监听八卦型)

2.1 Maxwell:轻量级监听者
# 启动Maxwell监听binlog
./bin/maxwell
--host=127.0.0.1
--user=maxwell
--password=xxx
--producer=kafka
--kafka.bootstrap.servers=localhost:9092
技术特点:
- 伪装成MySQL从库(潜伏技能MAX)
- 输出结构化JSON(ES:这个格式我熟)
- 支持过滤表/字段(选择性偷听)
优点:
- 业务零侵入(深藏功与名)
- 低延迟(速度堪比吃瓜群众)
- 支持断点续传(掉线了还能接上剧情)
缺点:
- 需要维护中间件(养猫就要铲屎的道理)
- 数据格式需转换(不能直接喂给ES)
2.2 Canal:阿里系老司机
// Canal客户端示例
CanalConnector connector = CanalConnectors.newClusterConnector(
"127.0.0.1:2181",
"example",
"",
"");
connector.connect();
connector.subscribe(".*\..*");
进阶功能:
- 集群部署(人多力量大)
- 数据过滤正则表达式(精准吃瓜)
- Prometheus监控(给老司机装仪表盘)
性能对比:
| 指标 | Maxwell | Canal |
|---|---|---|
| 吞吐量 | 5w QPS | 10w QPS |
| 内存占用 | 1GB | 2GB |
| 同步延迟 | <1s | <500ms |
| 学习成本 | ★★☆ | ★★★☆ |
方案3:ETL工具(老干部型)
Logstash JDBC Input
input {
jdbc {
jdbc_driver_library => "mysql.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/db"
jdbc_user => "root"
schedule => "* * * * *" # 每分钟像闹钟一样催一次
statement => "SELECT * FROM orders WHERE update_time > :sql_last_value"
}
}
适用场景:
- 定时全量同步(适合佛系数据)
- 千万级以下数据量(超出请自备降压药)
方案4:中间件代理(霸道总裁型)
ShardingSphere SQL解析
INSERT INTO t_order (...) VALUES (...);
↓
SQL解析引擎:这个数据要复制给ES!
↓
MySQL ES
黑科技:
- 自动SQL解析(数据库界的同声传译)
- 支持分库分表(霸道总裁的掌控力)
- 双写事务控制(要么全成功,要么全滚蛋)
缺点:
- 学习曲线陡峭(堪比爬华山)
- 代理层性能损耗(过路费总要交的)
方案5:云服务全家桶(氪金玩家专属)
阿里云DTS
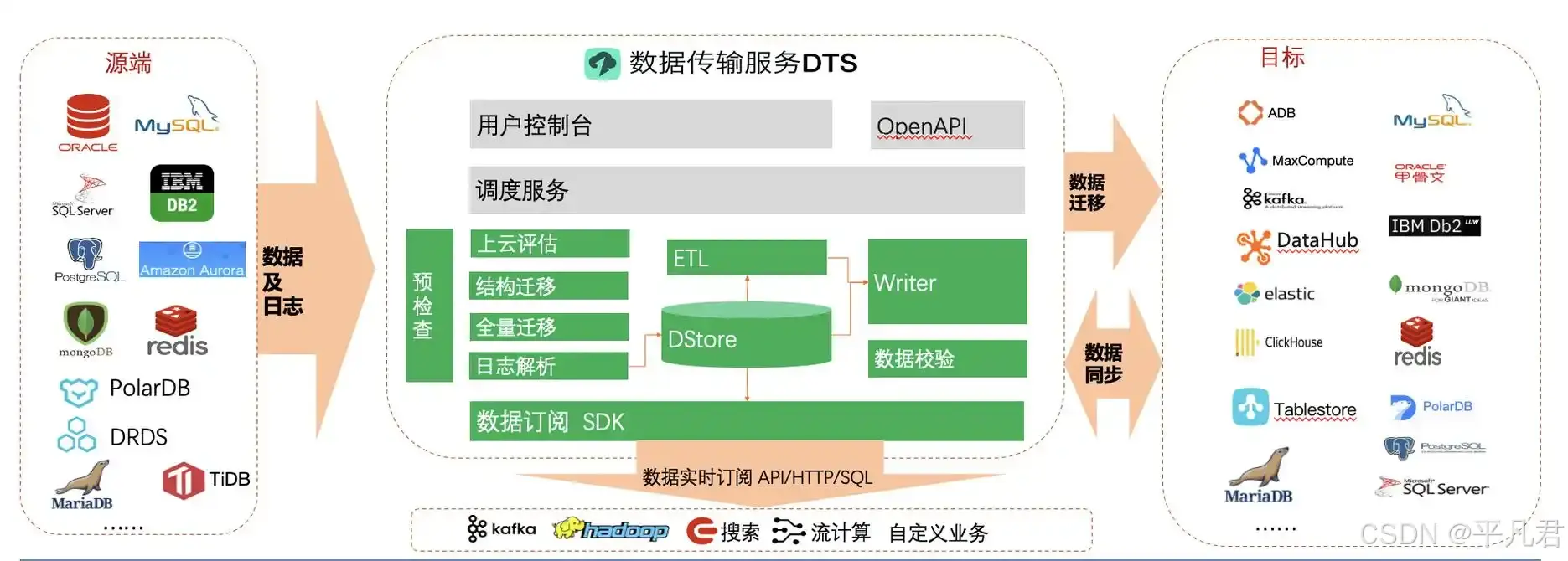
- 全自动同步(懒人终极梦想)
- 支持跨云同步(阿里腾讯世纪牵手)
- 按数据量收费(金钱换头发)
三、华山论剑:方案对比表
| 维度 | 双写 | Maxwell | Canal | Logstash | 中间件代理 | 云服务 |
|---|---|---|---|---|---|---|
| 实时性 | ★★★★★ | ★★★★☆ | ★★★★★ | ★★☆ | ★★★★☆ | ★★★★★ |
| 数据一致性 | ★★☆ | ★★★★☆ | ★★★★☆ | ★★★☆ | ★★★★★ | ★★★★★ |
| 大数据量处理 | ★★☆ | ★★★★☆ | ★★★★★ | ★★★☆ | ★★★★☆ | ★★★★★ |
| 系统侵入性 | ★☆☆ | ★★★★★ | ★★★★★ | ★★★★☆ | ★★☆☆☆ | ★★★★★ |
| 运维复杂度 | ★★☆ | ★★★☆ | ★★★★☆ | ★★★☆ | ★★★★★ | ★☆ |
| 学习成本 | ★☆☆ | ★★★☆ | ★★★★☆ | ★★★☆ | ★★★★★ | ★☆☆ |
| 适合数据规模 | <1亿 | <10亿 | 10亿+ | <5千万 | 10亿+ | 无上限 |
四、选型建议(防秃指南)
- 初创团队:Maxwell+MQ(性价比之选)
- 存量系统改造:Calan集群(老系统换新颜)
- 云环境优先:直接DTS(能用钱解决的别用头发)
- 分库分表场景:ShardingSphere(一统江湖的野心)
- 定时统计分析:Logstash(佛系玩家的选择)
最后提醒:没有银弹!选型就像谈恋爱,合适最重要(当然,能白嫖的方案最香)!
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结